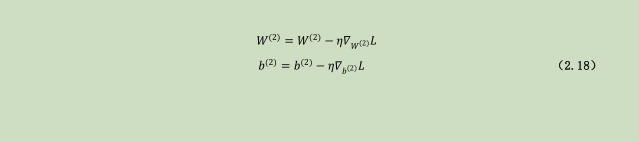写在前面 眨眼间,一周的时间从指间悄然流逝。今天要做的是“基于神经网络的手写数字识别”。2021.12.6
基于神经网络的手写数字识别 实验目的 掌握神经网络的设计原理,熟练掌握神经网络的训练和使用方法,能够使用Python语言,针对手写数字分类的训练和使用,实现一个三层全连接神经网络模型。具体包括:
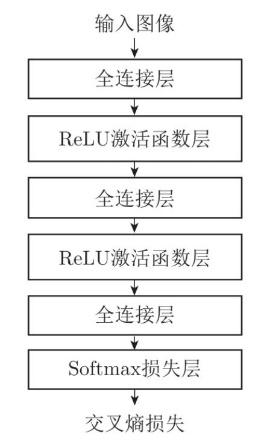
背景知识 神经网络的组成 一个完整的神经网络通常由多个基本的网络层堆叠而成。本实验中的三层全连接神经网络由三个全连接层构成,在每两个全连接层之间插入 ReLU 激活函数以引入非线性变换,最后使用 Softmax 层计算交叉熵损失,如图 2.1 所示。因此本实验中使用的基本单元包括全连接层、ReLU 激活函数、Softmax 损失函数。
全连接层 全连接层以一维向量作为输入,输入与权重相乘后再与偏置相加得到输出向量。假设全连接层的输入为 m维列向量 x,输出为 n 维列向量 y。
全连接层的权重 W 是二维矩阵,维度为 m×n,偏置 b 是 n 维列向量。前向传播时,全连接层的输出的计算公式为(注意偏置可以是向量,计算每一个输出使用不同的值;偏置也可以是一个标量,计算同一层的输出使用同一个值)
UReLU激活函数
Softmax 损失层
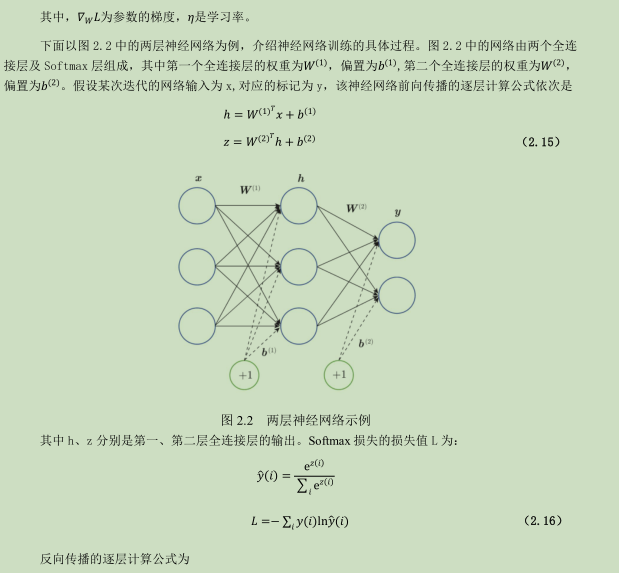
神经网络训练
示例代码 数据集 数据集采用 MNIST 手写数字库(老师直接提供,也可在 http://yann.lecun.com/exdb/mnist/自行下载)。该数据集包含一个训练集和一个测试集,其中训练集有 60000 个样本,测试集有 10000 个样本。每个样本都由灰度图像(即单通道图像)及其标记组成,图像大小为 28×28。MNIST 数据集包含 4 个文件,分别是训练集图像、训练集标记、测试集图像、测试集标记 。
总体设计 设计一个三层神经网络实现手写数字图像分类。该网络包含两个隐层和一个输出层,其中输入神经元个数由输入数据维度决定,输出层的神经元个数由数据集包含的类别决定,两个隐层的神经元个数可以作为超参数自行设置。对于手写数字图像的分类问题,输入数据为手写数字图像,原始图像一般可表示为二维矩阵(灰度图像)或三维矩阵(彩色图像),在输入神经网络前会将图像矩阵调整为一维向量作为输入。待分类的类别数一般是提前预设的,如手写数字包含 0 至 9 共 10 个类别,则神经网络的输出神经元个数为 10。
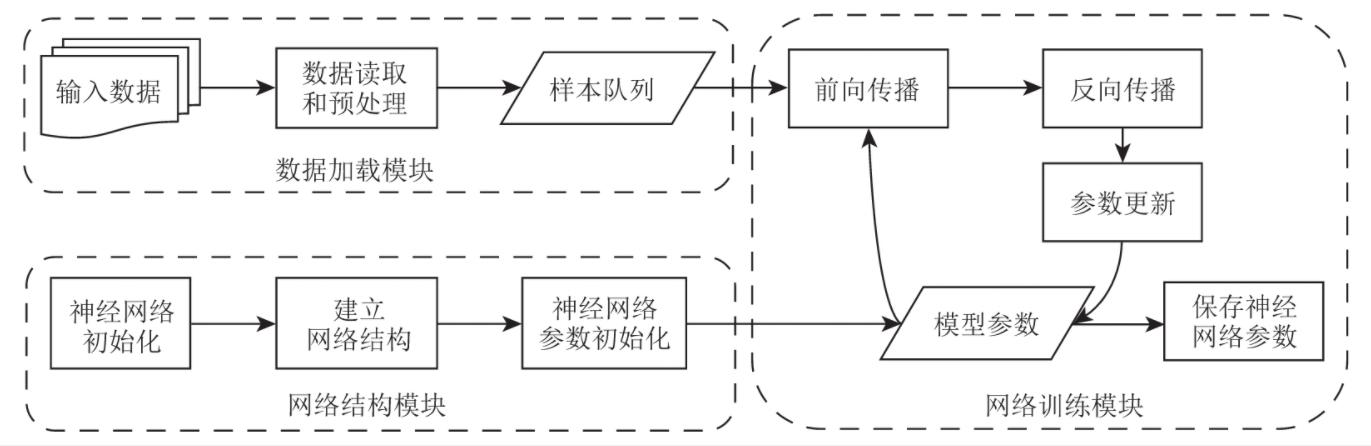
为了便于迭代开发,工程实现时采用模块化的方式来实现整个神经网络的处理,共划分为5大模块:
1)数据加载模块:从文件中读取数据,并进行预处理,其中预处理包括归一化、维度变换等处理。如果需要人为对数据进行随机数据扩增,则数据扩增处理也在数据加载模块中实现。
数据加载模块 本实验釆用的数据集是MNIST手写数字库。该数据集中的图像数据和标记数据采用表2.1中的IDX文件格式存放。图像的像素值按行优先顺序存放,取值范围为[0,255],其中0表示黑色,255表示白色。
首先编写读取 MNIST 数据集文件并预处理的子函数,程序示例如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def load_mnist (self, file_dir, is_images = 'True' ):open (file_dir, 'rb' )if is_images:'>iiii' 0 )else :'>ii' 0 )1 , 1 '>' + str (data_size) + 'B' , bin_data, struct.calcsize(fmt_header))'Load images from %s, number: %d, data shape: %s' % (file_dir, num_images, str (mat_data.shape)))return mat_data
然后调用该子函数对 MN1ST 数据集中的 4 个文件分别进行读取和预处理,并将处理过的训练和测试数据存储在 NumPy矩阵中(训练模型时可以快速读取该矩阵中的数据)。实现该功能的程序示例如下 所示。
1 2 3 4 5 6 7 8 9 10 def load_data (self ):'Loading MNIST data from files...' )True )1 )1 )
TODO 提示:代码中已有如下定义,直接按照 train_images 的代码套用即可:
基本单元模块
全连接层的实现示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class FullyConnectedLayer (object def __init__ (self, num_input, num_output ):'\tFully connected layer with input %d, output %d.' % (self.num_input, self.num_output))def init_param (self, std=0.01 ):0.0 , scale=std, size=(self.num_input, self.num_output))1 , self.num_output])def forward (self, input ):input = input return self.outputdef backward (self, top_diff ):return bottom_diffdef update_param (self, lr ):def load_param (self, weight, bias ):assert self.weight.shape == weight.shapeassert self.bias.shape == bias.shapedef save_param (self ):return self.weight, self.bias
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class ReLULayer (object def __init__ (self ):'\tReLU layer.' )def forward (self, input ):input = input return outputdef backward (self, top_diff ):input <0 ] = 0 return bottom_diff
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class SoftmaxLossLayer (object def __init__ (self ):'\tSoftmax loss layer.' )def forward (self, input ):max (input , axis=1 , keepdims=True )input - input_max)return self.probdef get_loss (self, label ):0 ]1.0 sum (np.log(self.prob) * self.label_onehot) / self.batch_sizereturn lossdef backward (self ):return bottom_diff
网络结构模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class MNIST_MLP (object def __init__ (self, batch_size=100 , input_size=784 , hidden1=32 , hidden2=16 , out_classes=10 , lr=0.01 , max_epoch=2 , print_iter=100 ):def build_model (self ):'Building multi-layer perception model...' )def init_model (self ):'Initializing parameters of each layer in MLP...' )for layer in self.update_layer_list:
网络训练( training) 神经网络训练流程如图2.9所示。在完成数据加载模块和网络结构模块实现之后,需要实现训练模块。本实验中三层神经网络的网络训练模块程序示例如图2.10所示。神经网络的训练模块通常拆解为若干步骤,包括神经网络的前向传播、神经网络的反向传播、神经网络参数更新、神经网络参数保存等基本操作。这些网络训练模块的基本操作以及训练主体用神经网络类的成员函数来定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 def forward (self, input ):input )return probdef backward (self ):def update (self, lr ):for layer in self.update_layer_list:def train (self ):0 ] // self.batch_size'Start training...' )for idx_epoch in range (self.max_epoch):for idx_batch in range (max_batch):1 )*self.batch_size, :-1 ]1 )*self.batch_size, -1 ]if idx_batch % self.print_iter == 0 :'Epoch %d, iter %d, loss: %.6f' % (idx_epoch, idx_batch, loss))
网络推断( inference ) 整个神经网络推断流程如图2.11所示。完成神经网络的训练之后,可以用训练得到的模型对测试数据进行预测,以评估模型的精度。工程实现中同样常将一个神经网络的推断模块拆解为若干步骤,包括神经网络模型参数加载、前向传播、精度计算等基本操作。这些网络推断模块的基本操作以及推断主体用神经网络类的成员函数来定义:
•神经网络的前向传播:网络推断模块中的神经网络前向传播操作与网络训练模块中的前向传播操作完全一致,因此可以直接调用网络训练模块中的神经网络前向传播函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def load_model (self, param_dir ):'Loading parameters from file ' + param_dir)True ).item()'w1' ], params['b1' ])'w2' ], params['b2' ])'w3' ], params['b3' ])def evaluate (self ):0 ]])for idx in range (self.test_data.shape[0 ]//self.batch_size):1 )*self.batch_size, :-1 ]1 )1 )*self.batch_size] = pred_labels"All evaluate time: %f" %(time.time()-start_time))1 ])'Accuracy in test set: %f' % accuracy)
完整实验流程 完成神经网络的各个模块之后,调用这些模块就可以实现用三层神经网络进行手写数字图像分类的完整流程。。首先实例化三层神经网络对应的类,指定神经网络的超参数,如每层的神经元个数。其次进行数据的加载和预处理。再调用网络结构模块建立神经网络,随后进行网络初始化,在该过程中网络结构模块会自动调用基本单元模块实例化神经网络中的每个层。然后调用网络训练模块训练整个网络,之后将训练得到的模型参数保存到文件中。最后从文件中读取训练得到的模型参数,之后调用网络推断模块测试网络的精度。
1 2 3 4 5 6 7 8 9 10 11 12 if __name__ == '__main__' :32 , 16 , 1 "All train time: %f" %(time.time()-start_time))'mlp-%d-%d-%depoch.npy' % (h1, h2, e))'mlp-%d-%d-%depoch.npy' % (h1, h2, e))
实验评估
实验内容 1)请在代码中有TODO的地方填空,将程序补充完整,在报告中写出相应代码,并给出自己的理解。
5)最 终 evaluate()函数输出的 Accuracy in test set 是多少?请想办法提高该数值。本小题的评估标准设定如下:
实验结果与分析 步骤解析 数据加载模块 1 2 3 4 5 6 7 8 9 10 def load_data (self ):'Loading MNIST data from files...' )True )False )True )False )1 )1 )
加载数据集,train_labels、train_images、test_images、test_labels。MNIST_DIR用于定位文件,True代表加载图像,False代表加载标签。
基本单元模块 全连接层 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class FullyConnectedLayer (object def __init__ (self, num_input, num_output ):'\tFully connected layer with input %d, output %d.' % (self.num_input, self.num_output))def init_param (self, std=0.01 ):0.0 , scale=std, size=(self.num_input, self.num_output))1 , self.num_output])def forward (self, input ):input = input return self.outputdef backward (self, top_diff ):input .T,top_diff)return bottom_diffdef update_param (self, lr ):def load_param (self, weight, bias ):assert self.weight.shape == weight.shapeassert self.bias.shape == bias.shapedef save_param (self ):return self.weight, self.bias
ReLU层 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class ReLULayer (object def __init__ (self ):'\tReLU layer.' )def forward (self, input ):input = input input ,0 )return outputdef backward (self, top_diff ):input <0 ] = 0 return bottom_diff
Softmax层 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class SoftmaxLossLayer (object def __init__ (self ):'\tSoftmax loss layer.' )def forward (self, input ):max (input , axis=1 , keepdims=True )input - input_max)sum (input_exp,axis=1 ),(10 ,1 )).Treturn self.probdef get_loss (self, label ):0 ]1.0 sum (np.log(self.prob) * self.label_onehot) / self.batch_sizereturn lossdef backward (self ):return bottom_diff
网络结构模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class MNIST_MLP (object def __init__ (self, batch_size=100 , input_size=784 , hidden1=32 , hidden2=16 , out_classes=10 , lr=0.01 , max_epoch=2 , print_iter=100 ):def build_model (self ):'Building multi-layer perception model...' )def init_model (self ):'Initializing parameters of each layer in MLP...' )for layer in self.update_layer_list:
网络训练模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 def forward (self, input ):input )return probdef backward (self ):def update (self, lr ):for layer in self.update_layer_list:def train (self ):0 ] // self.batch_size'Start training...' )for idx_epoch in range (self.max_epoch):for idx_batch in range (max_batch):1 )*self.batch_size, :-1 ]1 )*self.batch_size, -1 ]if idx_batch % self.print_iter == 0 :'Epoch %d, iter %d, loss: %.6f' % (idx_epoch, idx_batch, loss))
shuffle的作用及max_batch的意义 max_batch = self.train_data.shape[0] // self.batch_size 表示分组,即一个样本计算一次偏导更新一次权值还是多个样本计算一次偏导,更新一次权值。
以猫狗分类为例, 假如数据集是
Dog,Dog,Dog,… ,Dog,Dog,Dog,Cat,Cat,Cat,Cat,… ,Cat,Cat
所有的狗都在猫前面,如果不shuffle,模型训练一段时间内只看到了Dog,必然会过拟合于Dog,一段时间内又只能看到Cat,必然又过拟合于Cat,这样的模型泛化能力必然很差。 那如果Dog和Cat一直交替,会不会就不过拟合了呢?
Dog,Cat,Dog,Cat,Dog ,Cat,Dog,…
依然会过拟合,模型是会记住训练数据路线的,为什么呢?
当用随机梯度下降法训练神经网络时,通常的做法是洗牌数据。在纠结细节的情况下,让我们用一个极端的例子来解释为什么shuffle是有用的。假设你正在训练一个分类器来区分猫和狗,你的训练集是50,000只猫后面跟着50,000只狗。如果你不洗牌,你的训练成绩就会很差。 严格地说,这个问题是由梯度噪声中的序列相关性和参数更新的不可交换性引起的。首先我们需要明白固定的数据集顺序,意味着给定迭代步,对应此迭代步的训练数据是固定的。 假如目标函数是J=f(w,b)J=f(w,b),使用梯度下降优化JJ。给定权重取值w、bw、b和迭代步step的情况下,固定的数据集顺序意味着固定的训练样本,也就意味着权值更新的方向是固定的,而无顺序的数据集,意味着更新方向是随机的。所以固定的数据集顺序,严重限制了梯度优化方向的可选择性,导致收敛点选择空间严重变少,容易导致过拟合。所以模型是会记住数据路线的,所以shuffle很重要,一定shuffle。
摘自 https://deepindeed.cn/2019/12/23/Data-Shuffle/
完整代码: 全连接神经网络 layers_1.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import numpy as npimport structimport osimport timeclass FullyConnectedLayer (object def __init__ (self, num_input, num_output ):'\tFully connected layer with input %d, output %d.' % (self.num_input, self.num_output))def init_param (self, std=0.01 ):0.0 , scale=std, size=(self.num_input, self.num_output))1 , self.num_output])def forward (self, input ):input = input input ,self.weight)+self.biasreturn self.outputdef backward (self, top_diff ):input .T,top_diff)return bottom_diffdef update_param (self, lr ):def load_param (self, weight, bias ):assert self.weight.shape == weight.shapeassert self.bias.shape == bias.shapedef save_param (self ):return self.weight, self.biasclass ReLULayer (object def __init__ (self ):'\tReLU layer.' )def forward (self, input ):input = input input ,0 )return outputdef backward (self, top_diff ):input <0 ] = 0 return bottom_diffclass SoftmaxLossLayer (object def __init__ (self ):'\tSoftmax loss layer.' )def forward (self, input ):max (input , axis=1 , keepdims=True )input - input_max)sum (input_exp,axis=1 ),(10 ,1 )).Treturn self.probdef get_loss (self, label ):0 ]1.0 sum ( self.label_onehot*np.log(self.prob)) / self.batch_sizereturn lossdef backward (self ):return bottom_diff
mnist_mlp_cpu.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 import numpy as npimport structimport osimport timefrom layers_1 import FullyConnectedLayer, ReLULayer, SoftmaxLossLayer"./mnist_data" "train-images-idx3-ubyte" "train-labels-idx1-ubyte" "t10k-images-idx3-ubyte" "t10k-labels-idx1-ubyte" def show_matrix (mat, name ):pass class MNIST_MLP (object def __init__ (self, batch_size=100 , input_size=784 , hidden1=32 , hidden2=16 , out_classes=10 , lr=0.01 , max_epoch=2 , print_iter=100 ):def load_mnist (self, file_dir, is_images = 'True' ):open (file_dir, 'rb' )if is_images:'>iiii' 0 )else :'>ii' 0 )1 , 1 '>' + str (data_size) + 'B' , bin_data, struct.calcsize(fmt_header))'Load images from %s, number: %d, data shape: %s' % (file_dir, num_images, str (mat_data.shape)))return mat_datadef load_data (self ):'Loading MNIST data from files...' )True )False )True )False )1 )1 )def shuffle_data (self ):'Randomly shuffle MNIST data...' )def build_model (self ):'Building multi-layer perception model...' )def init_model (self ):'Initializing parameters of each layer in MLP...' )for layer in self.update_layer_list:def load_model (self, param_dir ):'Loading parameters from file ' + param_dir)True ).item()'w1' ], params['b1' ])'w2' ], params['b2' ])'w3' ], params['b3' ])def save_model (self, param_dir ):'Saving parameters to file ' + param_dir)'w1' ], params['b1' ] = self.fc1.save_param()'w2' ], params['b2' ] = self.fc2.save_param()'w3' ], params['b3' ] = self.fc3.save_param()def forward (self, input ):input )return self.probdef backward (self ):def update (self, lr ):for layer in self.update_layer_list:def train (self ):0 ] // self.batch_size'Start training...' )for idx_epoch in range (self.max_epoch):for idx_batch in range (max_batch):1 )*self.batch_size, :-1 ]1 )*self.batch_size, -1 ]if idx_batch % self.print_iter == 0 :'Epoch %d, iter %d, loss: %.6f' % (idx_epoch, idx_batch, loss))def evaluate (self ):0 ]])for idx in range (self.test_data.shape[0 ]//self.batch_size):1 )*self.batch_size, :-1 ]1 )1 )*self.batch_size] = pred_labels"All evaluate time: %f" %(time.time()-start_time))1 ])'Accuracy in test set: %f' % accuracy)if __name__ == '__main__' :32 , 16 , 1 "All train time: %f" %(time.time()-start_time))'mlp-%d-%d-%depoch.npy' % (h1, h2, e))'mlp-%d-%d-%depoch.npy' % (h1, h2, e))
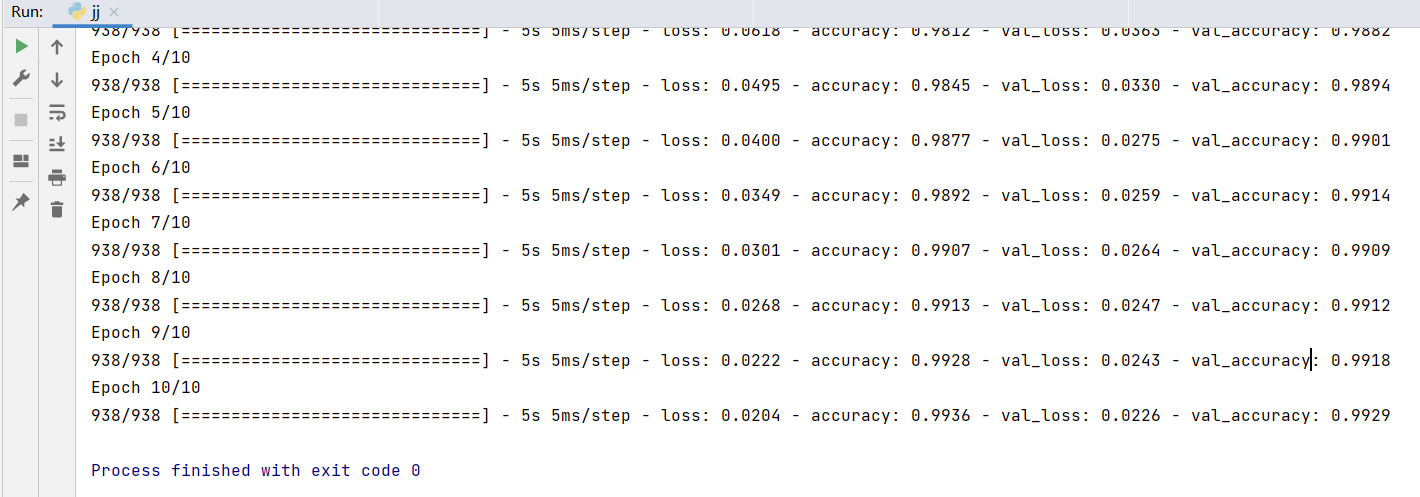
卷积神经网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense,Dropout,Flatten,Convolution2D,MaxPooling2Dfrom tensorflow.keras.optimizers import Adamimport matplotlib.pyplot as pltimport numpy as np1 ,28 ,28 ,1 )/255.0 1 ,28 ,28 ,1 )/255.0 10 )10 )28 ,28 ,1 ),32 ,5 ,1 ,'same' ,'relu' 2 ,2 ,'same' 64 ,5 ,strides = 1 ,padding = 'same' ,activation = 'relu' ))2 ,2 ,'same' ))1024 ,activation='relu' ))0.5 ))10 ,activation = 'softmax' ))1e-4 )compile (optimizer=adam,loss='categorical_crossentropy' ,metrics=['accuracy' ])64 ,epochs = 10 ,validation_data = (x_test,y_test))'mnist.h5' )
效果: