
计算智能课程设计(遗传算法求解无约束单目标优化问题)
写在前面
前天写完了基于传递闭包的模糊聚类,今天准备写“遗传算法求解无约束单目标优化问题”。昨天和npy玩了一下午,去齐白石艺术学院看了画展,一起在最高处看了夕阳,并在落日前接吻。
实验题目
遗传算法求解无约束单目标优化问题
实验目的
理解遗传算法原理,掌握遗传算法的基本求解步骤,包括选择、交叉、变异等,学会运用遗传算法求解无约束单目标优化问题。
背景知识
遗传算法(Genetic Algorithm)是借鉴生物界自然选择、适者生存遗传机制的一种随机搜索方法。遗传算法模拟了进化生物学中的遗传、突变、自然选择以及杂交等现象,是进化算法的一种。对于一个最优化问题,一定数量的候选解(每个候选解称为一个个体)的抽象表示(也称为染色体)的种群向更好的方向解进化,通过一代一代不断繁衍,使种群收敛于最适应的环境,从而求得问题的最优解。进化从完全随机选择的个体种群开始,一代一代繁殖、进化。在每一代中,整个种群的每个个体的适应度被评价,从当前种群中随机地选择多个个体(基于它们的适应度),通过自然选择、优胜劣汰和突变产生新的种群,该种群在算法的下一次迭代中成为当前种群。传统上,解一般用二进制表示(0 和 1 组成的串)。遗传算法的主要特点是直接对结构对象进行操作,不存在函数求导、连续、单峰的限定;具有内在的隐闭并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化搜索,自适应调整搜索方向,不需要确定的规则。遗传算法已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工智能等领域中的问题求解,已成为现代智能计算中的一项关键技术。
关键术语:
(1)个体( individuals):遗传算法中所处理的对象称为个体。个体通常可以含解的编码表示形式、适应度值等构成成分,因而可看成是一个结构整体。其中,主要成分是编码。
(2)种群(population):由个体构成的集合称为种群。
(3)位串(bit string):解的编码表示形式称为位串。解的编码表示可以是 0、1 二值串、0~9 十进制数字串或其他形式的串,可称为字符串或简称为串。位串和染色体(chromosome)相对应。在遗传算法的描述中,经常不加区分地使用位串和染色体这两个概念。位串/染色体与个体的关系:位串/染色体一般是个体的成分,个体还可含有适度值等成分。个体、染色体、位串或字符串有时在遗传算法中可不加区分地使用。
(4)种群规模(population scale):又称种群大小,指种群中所含个体的数目。
(5)基因(gene):位串中的每个位或元素统称为基因。基因反映个体的特征。同一位上的基因不同,个体的特征可能也不相同。基因对应于遗传学中的遗传物质单位。在 DNA 序列表示中,遗传物质单位也是用特定编码表示的。遗传算法中扩展了编码的概念,对于可行解,可用 0、1 二值、0~9 十个数字,以及其他形式的编码表示。例如,在 0、1 二值编码下,有一个串 S=1011,则其中的 1,0,1,1这 4 个元素分别称为基因。基因和位在遗传算法中也可不加区分地使用。
(6)适应度(fitness):个体对环境的适应程度称为适应度(fitness)。为了体现染色体的适应能力,通常引入一个对每个染色体都能进行度量的函数﹐称为适应度函数。
(7)选择(selection):在整个种群或种群的一部分中选择某个个体的操作。
(8)交叉(crossover):两个个体对应的一个或多个基因段的交换操作。
(9)变异(mutation):个体位串上某个基因的取值发生变化。如在 0、1 串表示下,某位的值从 0 变为 1,或由 1 变为 0。
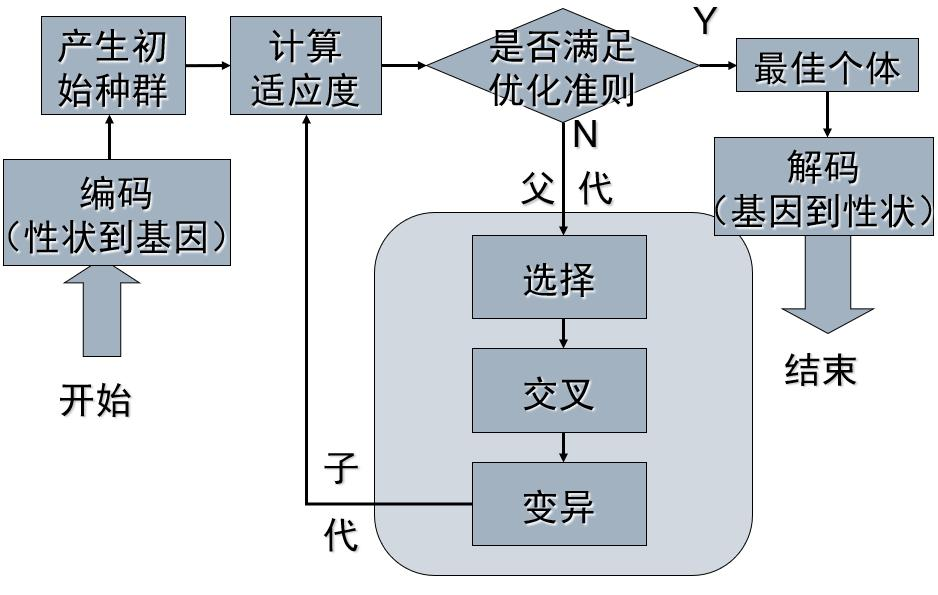
遗传算法的基本流程如下:
本案例意在说明如何使用遗传算法求解无约束单目标优化问题,即求一元函数:

在区间[-1, 2]上的最大值。该函数图像如下:
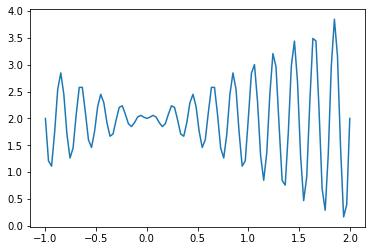
由图像可知该函数在在区间[-1, 2]上有很多极大值和极小值,对于求其最大值或最小值的问题,很多单点优化的方法(梯度下降等)就不适合,这种情况下可以考虑使用遗传算法。。
示例代码
1 | |
实验内容
运行和理解示例代码,回答下列问题:
1)代码第 64 行的语义是什么?两个[0]各自代表什么?最后 newX 有几个元素?
1 | |
2)代码第 70 行的语义是什么?为什么要除以 2 再乘以 2?reshape 中的-1 表示什么?
1 | |
3)请结合 Mutate 函数的内容,详述变异是如何实现的。
4)将代码第 145 行修改为 newchroms = Select_Crossover(chroms, fitness),即不再执行变异,执行结果有什么不同,为什么会出现这种变化?
5)轮盘让个体按概率被选择,对于适应度最高的个体而言,虽然被选择的概率高,但仍有可能被淘汰,从而在进化过程中失去当前最优秀的个体。一种改进方案是,让适应度最高的那个个体不参与选择,而是直接进入下一轮(直接晋级),这种方案被称为精英选择(elitist selection)。请修改Select 部分的代码,实现这一思路。
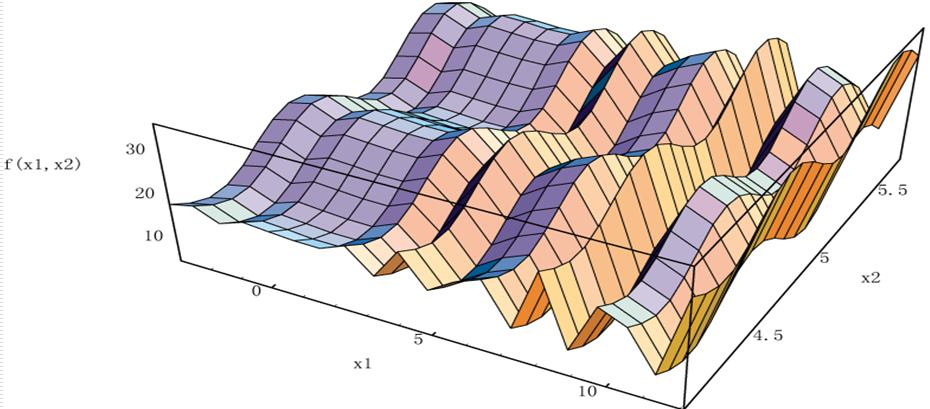
6)【选做】请借鉴示例代码,实现教材 P57 的例 2.6.1,即用遗传算法求解下列二元函数的最大值。



实验结果与分析
第一题
1)代码第 64 行的语义是什么?两个[0]各自代表什么?最后 newX 有几个元素?
1 | |
经过拆分,得到结果:

上面的代码等于
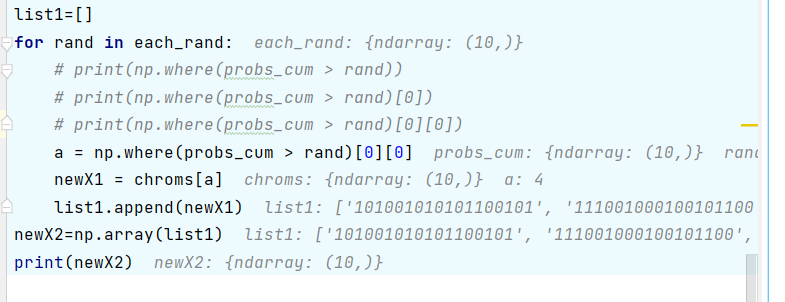
其中[]中的for为列表生成式,返回一个列表。第一个[0]表示np.where()生成tuple元组中数组的行索引,np.where()[0]的值是tuple中的第一个数组,第二个[0]是该数组的首位元素。
最后newX一共有100个元素。
第二题
2)代码第 70 行的语义是什么?为什么要除以 2 再乘以 2?reshape 中的-1 表示什么?
1 | |
随机生成6个在[0,5]之间的数字,并将其排列成二维的形状是(3,2)的数组。
prob可能是奇数,这样乘上去没法取到整数分组,所以要//2取整。染色体是两两配对,所以要乘2。
reshape中的-1表示,通过列数对数组的行数进行自动计算。新的shape属性应该要与原来的配套,如果等于-1的话,那么Numpy会根据剩下的维度计算出数组的另外一个shape属性值。
第三题
3)请结合 Mutate 函数的内容,详述变异是如何实现的。
1 | |
- 首先,得到变异概率与单个染色体的长度(二进制数位数),再利用字典对变异的两种情况做一个存储。
- newchroms是存放变异后新种群的array。
- 通过each_prob计算出每个染色体的随机变异概率
- 遍历染色体,如果随机变异概率低于变异概率,则发生变异
- 发生变异,通过计算pos,从染色体中随机找个位置变异,即二进制数某个位发生突变
- 无论染色体是否发生变异,都在新种群中添加染色体(发生突变的与岁月静好的都算)
- 返回整个新的种群
第四题
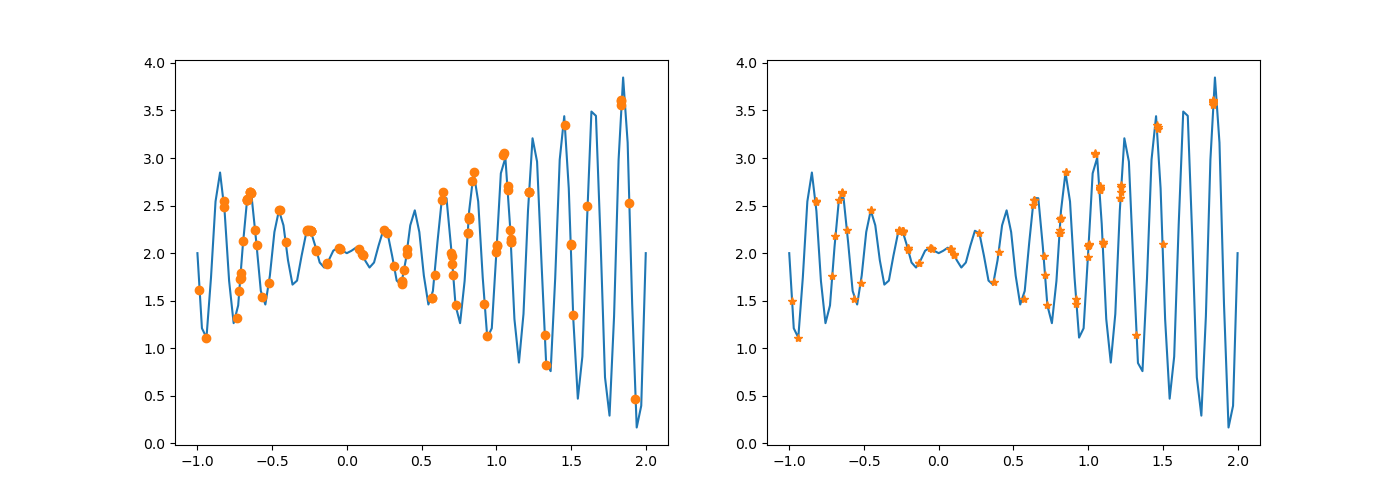
4)将代码第 145 行修改为 newchroms = Select_Crossover(chroms, fitness),即不再执行变异,执行结果有什么不同,为什么会出现这种变化?
未修改前:
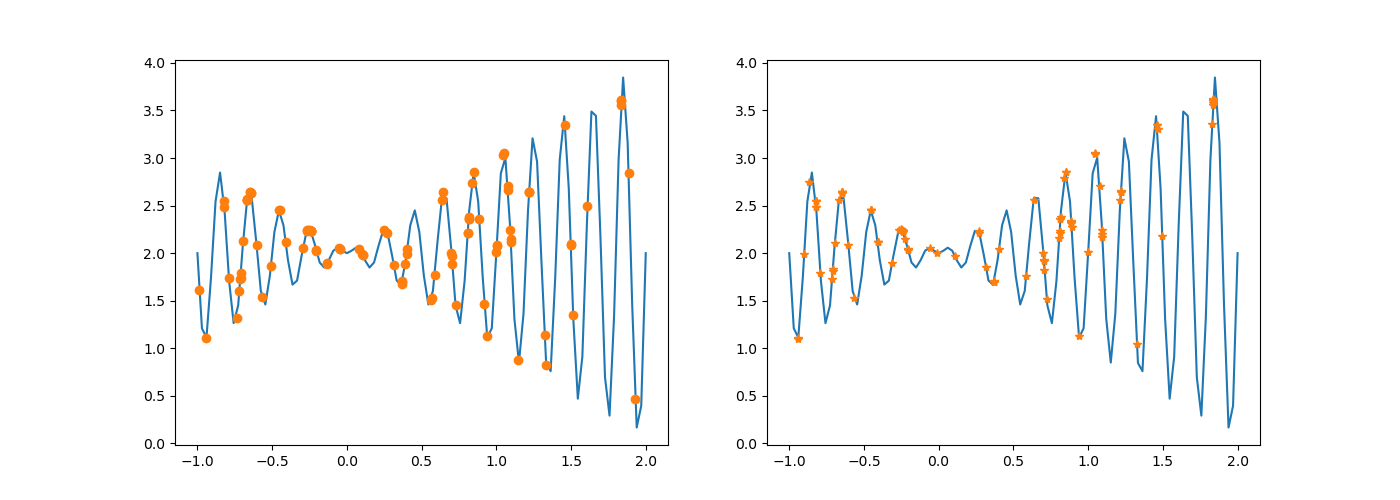
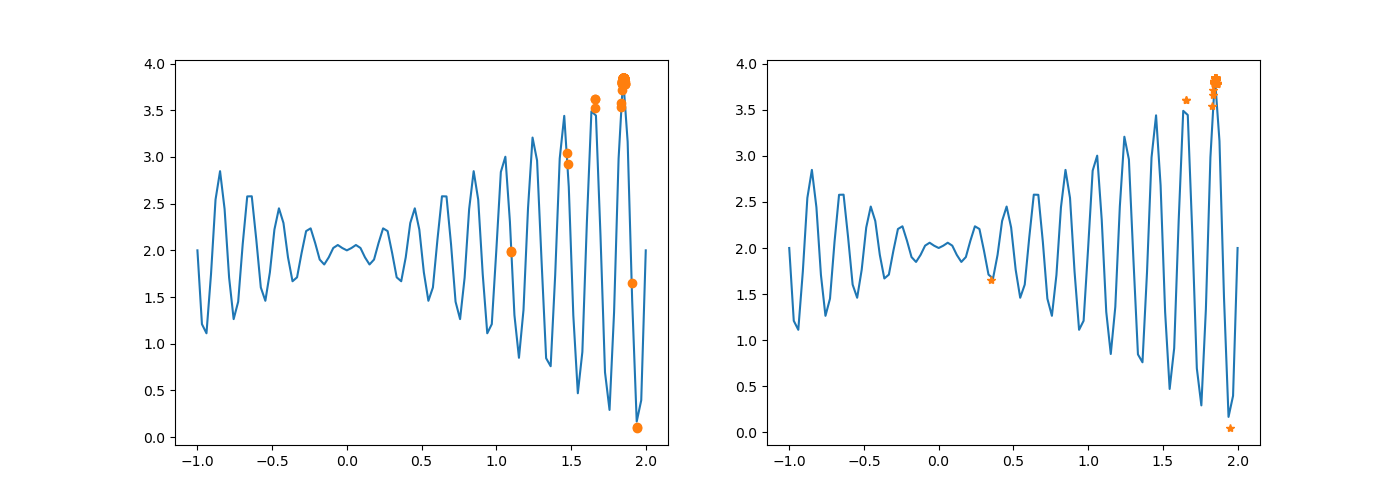
修改后:

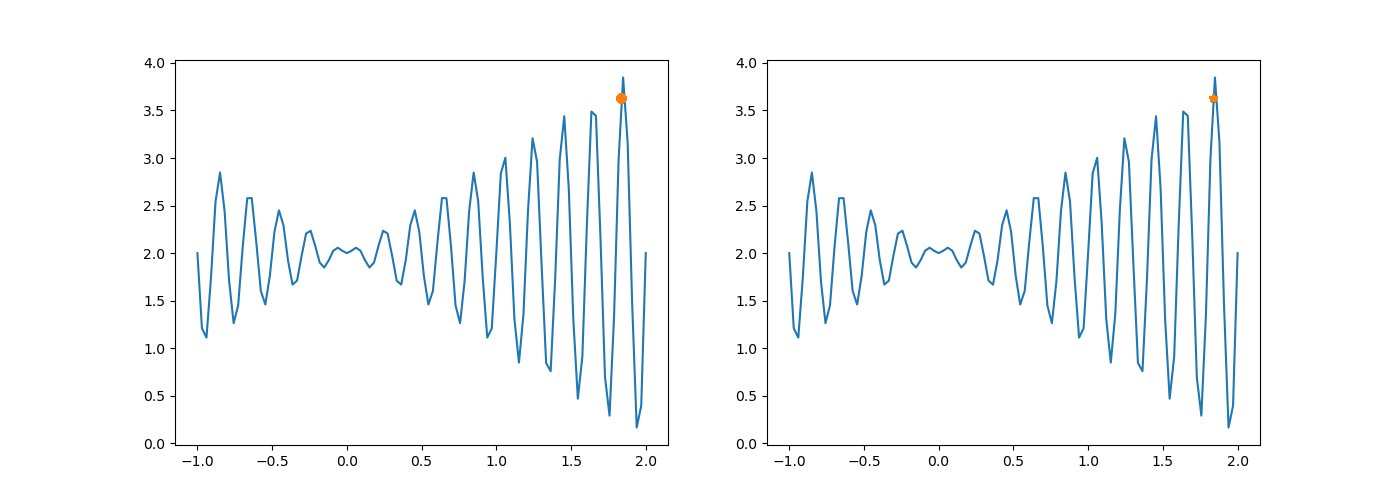
执行结果变化如上。
染色体进行过交叉后,不再发生变异。少了一次变异,新种群与原种群概率上讲,差异要更小一些。结果可能不会产生最大值。
第五题
5)轮盘让个体按概率被选择,对于适应度最高的个体而言,虽然被选择的概率高,但仍有可能被淘汰,从而在进化过程中失去当前最优秀的个体。一种改进方案是,让适应度最高的那个个体不参与选择,而是直接进入下一轮(直接晋级),这种方案被称为精英选择(elitist selection)。请修改Select 部分的代码,实现这一思路。
1 | |
第六题
代码思路
基于源代码与教材,对代码进行了如下修改:
因为要求二元函数的最大值,所以需要两个变量,x与y。这样一来,所需的种群就要有两批,设为chroms_x与chroms_y去对应,接下来需要对chroms1与chroms2进行编码和解码。代码如下。
1 | |
chroms_x的染色体长度为21,chroms_y的长度为18,在编写编码和解码的代码中,分别要写两个函数,有所不同。按题目要求,需要将两段种群基因拼接起来,所以还需要设置第三个拼接后的种群chroms_v,以及对应的编码函数。变异后,需要将两个种群重新拆离,生成chroms_x和chroms_y去求函数。这里就需要一个解码过程。代码如下:
1 | |
变异过程与源代码无异,只是将中心交叉改为了随机交叉。
1 | |
求出函数,要将数据可视化,我们作三维图进行对比表示。
1 | |
最后看一下主函数
1 | |
完整代码:
1 | |
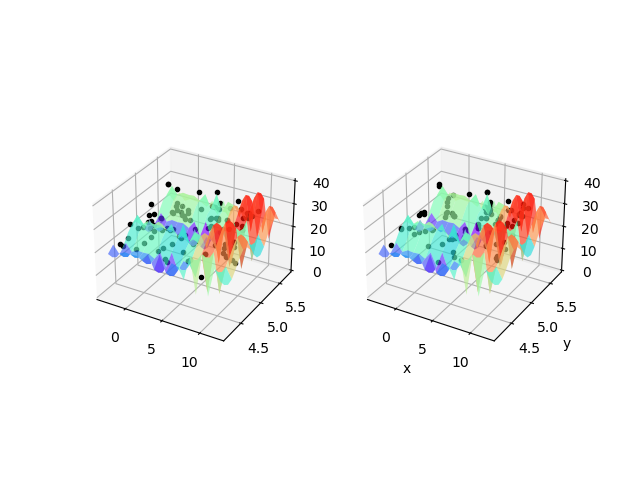
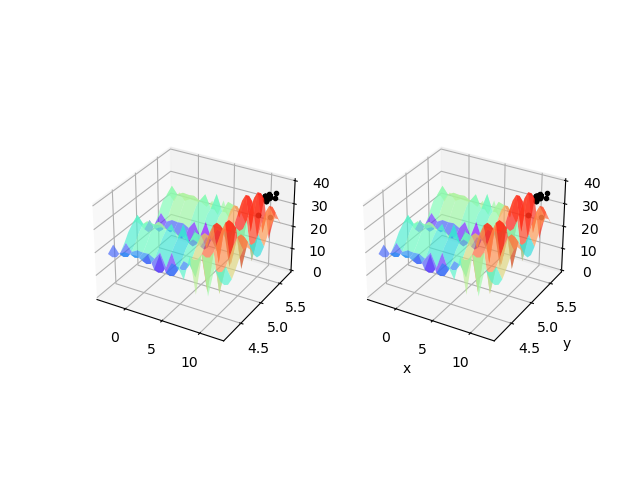
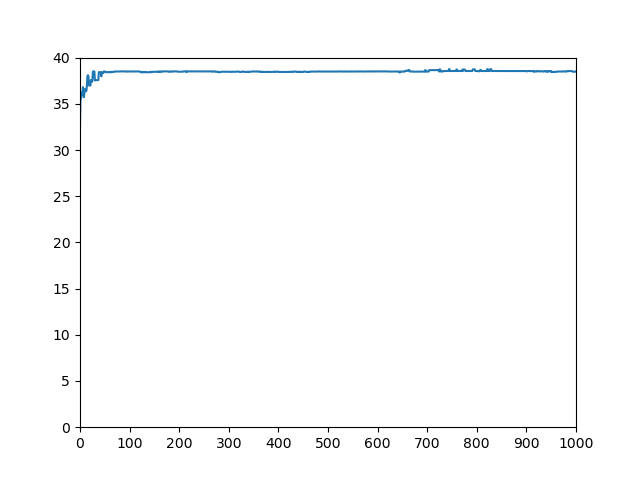
第六题代码来源:19级大数据三班 wcx

