
计算智能课程设计(基于感知机的鸢尾花分类)
写在前面
岁月匆匆,不知不觉已经步入了大三学年。专业课的学习也变得更加深入,今天要做的是计算智能的课程设计,基于感知机的鸢尾花分类。2021.11.29.
基于感知机的鸢尾花分类
实验目的
利用感知机算法对鸢尾花种类进行分类,要求熟悉感知机算法,掌握利用Python实现机器学习算法的一般流程,了解scikit-learn机器学习库的使用。
背景知识
植物的分类与识别是植物学研究和农林业生产经营中的重要基础工作,对于区分植物种类、探索植物间的亲缘关系、阐明植物系统的进化规律具有重要意义。传统识别植物的方法主要依靠人工,需要丰富的专业知识,工作量大,效率不高,而且难以保证分类的客观性和精确性。随着信息技术飞速发展,将计算机视觉、模式识别、数据库等技术应用于植物种类识别,使得识别更加简单、准确、易行。相对于植物的其它部分,其花朵图像更容易获取,花朵的颜色和形状等都可作为分类依据。本案例在提取花朵形态特征的基础上,利用感知机算法进行分类与识别。鸢(读音同”愿”)尾花,英文为 Iris,多年生草本植物,花大而美丽,叶片青翠碧绿,观赏价值很高,是一种重要的观赏用庭园植物。 其外形作为独特的徽章,在欧洲的宗教、皇室建筑上被广泛应用。特别是在法国,印在法国军旗上的三朵鸢尾花图案标志着法兰西王国的王权。鸢尾花有三个主要类型(种属): Setosa 山鸢尾、 Versicolour 变色鸢尾 和 Virginica 维吉尼亚鸢尾,其主要区别是萼片长度、萼片宽度、花瓣长度和花瓣宽度。

鸢尾花数据集:scikit-learn 是基于 Python 的机器学习库,其默认安装包含了几个小型的数据集,并提供了读取这些数据集的接口。 其中 sklearn.datasets.load_iris()用于读取鸢尾花数据集,该数据集有 150 组 3 种类型鸢尾花的 4 种属性:萼片长度 sepal length、萼片宽度 sepal width、花瓣长度 petallength 和花瓣宽度 petal width,样本编号与类型的关系是:样本编号 0 至 49 为 Setosa ,50 至 99 为Versicolour ,100 至 149 为 Virginica。
示例代码
1 ) 加载用到的库
1 | |
2 )加载鸢尾花数据集
1 | |
如前所述,scikit-learn 提供了读取鸢尾花数据集的接口 sklearn.datasets.load_iris(),该数据集有 150 组 3 种类型鸢尾花的 4 种属性:萼片长度 sepal length、萼片宽度 sepal width、花瓣长度 petal length 和花瓣宽度 petal width,样本编号与类型的关系是:样本编号 0 至 49 为 Setosa ,50 至 99 为Versicolour ,100 至 149 为 Virginica。代码 iris = load_iris()中得到的 iris 是一个字典,包含七个“key-value”对:
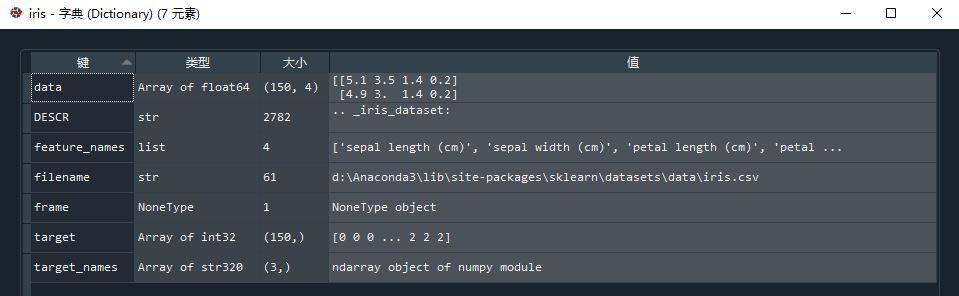
其中每一个 key 的意义和 value 说明如下:
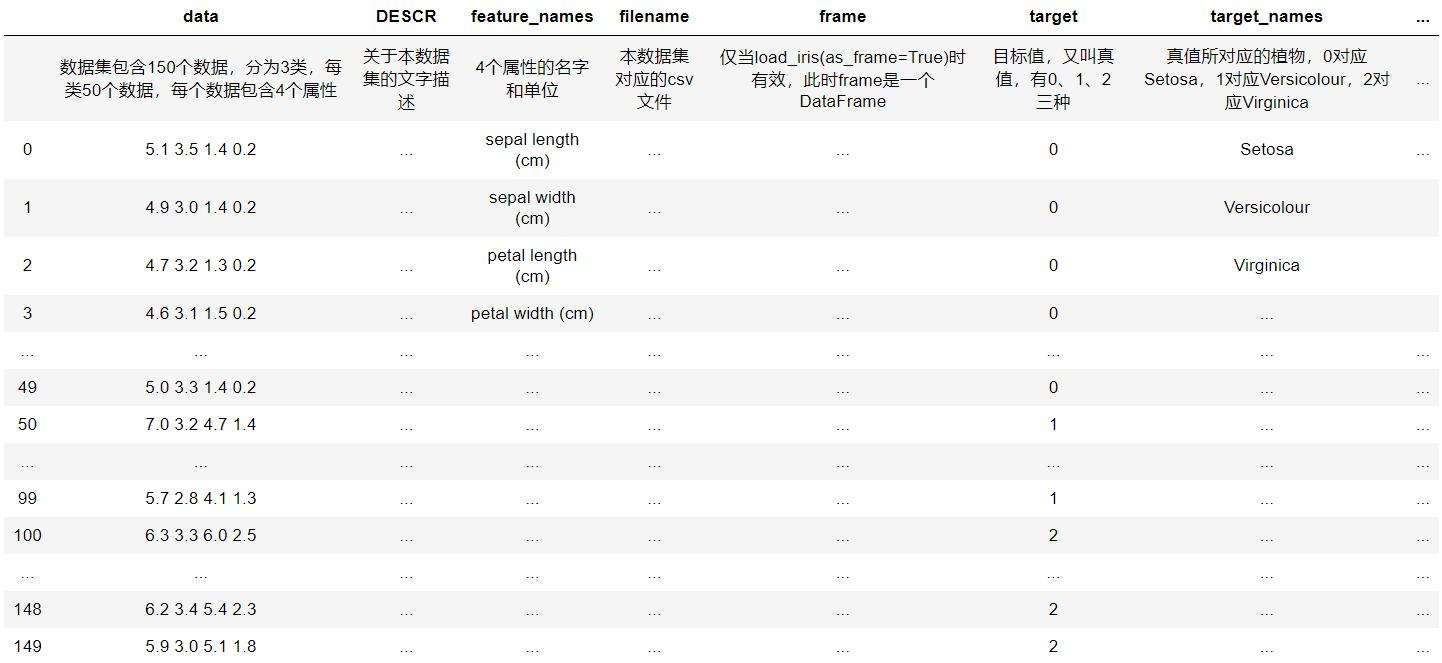
3)通过画图了解三种鸢尾花的分布
1 | |
生成图片如下:
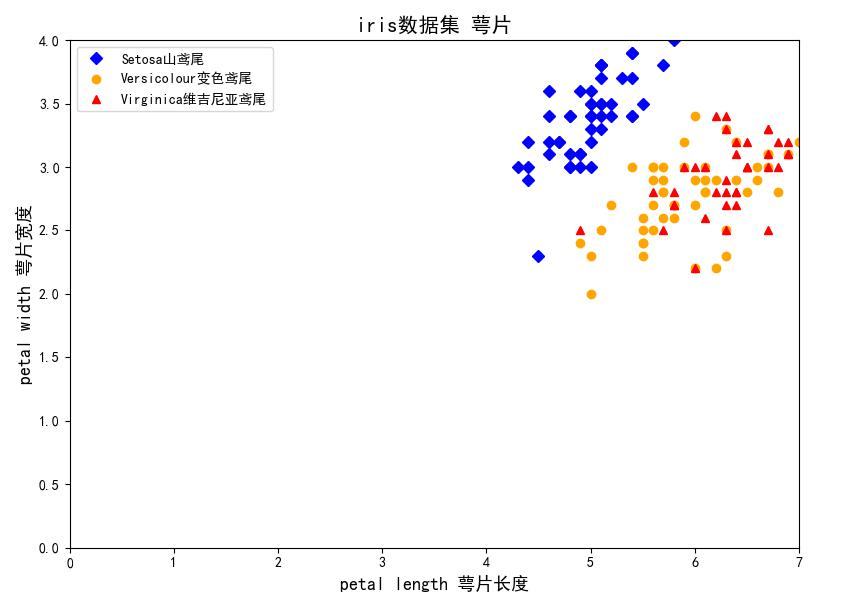
从图中大致可以看出,萼片长度和萼片宽度与鸢尾花类型间呈现出非线性关系。
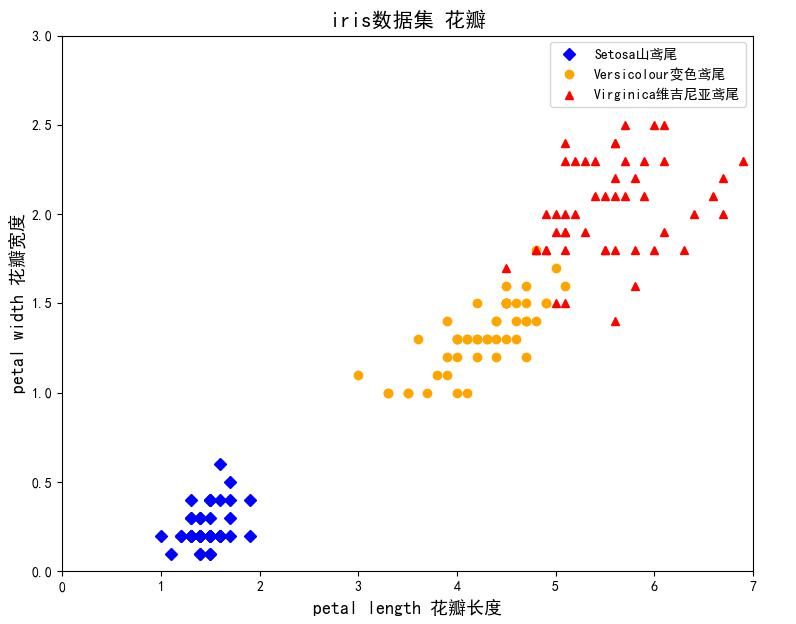
从图中大致可以看出,花瓣长度和花瓣宽度与鸢尾花类型间有较好的线性关系,使用花瓣数据来划分鸢尾花类型效果更好。
4 )算法初始化
1 | |
np.ones(100) 生成 100 行 1 列的 1,作为偏置的输入。
iris.data[:100,2:4] 得到前 100 行,2 列和 3 列数据,作为两个特征(花瓣长度、花瓣宽度)的输入。
np.c_是按行连接两个矩阵,就是把两矩阵左右相连形成一个新矩阵,要求行数相等。
组合两个特征和偏置,形成最终的输入 X。
X=(x0 x1 x2),即偏置、花瓣长度、花瓣宽度。
真值 T 直接从数据集中得到,然后将 T 中所有不等于 1 的元素赋值为-1,以契合接下来将要使用到的 sign 函数。
5 )学习算法
1 | |
6)画图函数
1 | |
7)主函数
1 | |
实验内容
请回答下列问题:
第一题
1.考虑学习率的作用。修改示例代码,固定初始权值=(1,1,1),将学习率分别设定为 1、0.5、0.1(组合 1~3),程序在 epoch 等于多少时实现分类?
- 当修改学习率为1时:
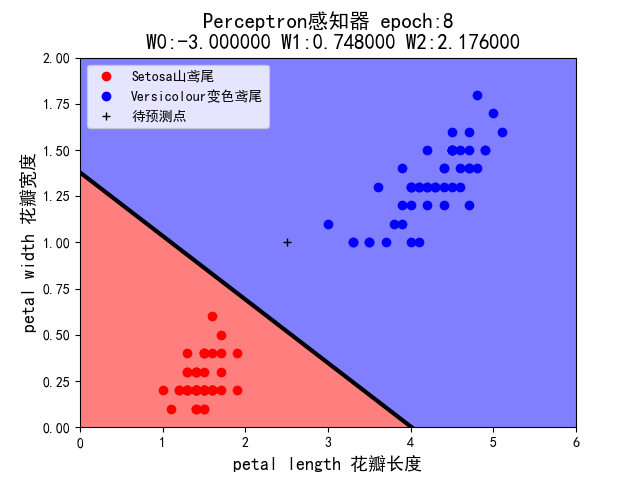
当修改学习率为0.5时:

当修改学习率为0.1时:
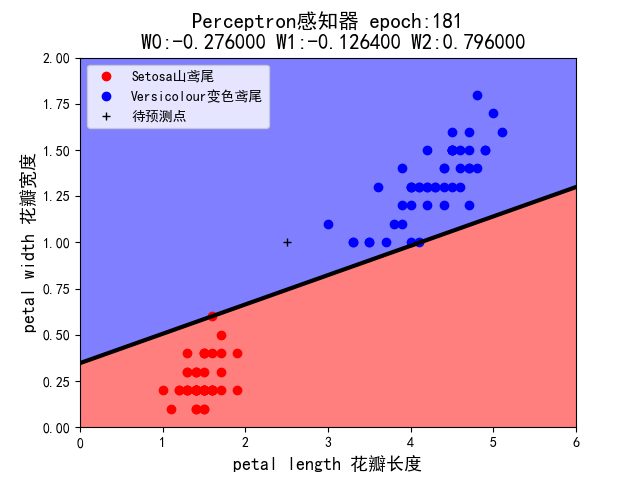
第二题
2.考虑初始权值的作用。修改示例代码,固定学习率=0.1,将初始权值分别设定为(-1,1,1)、(+1,-1,-1)、(1,-1,+1) 、(-1,+1,-1) (组合 4~7),程序在 epoch 等于多少时实现分类?
当初始权值设定为(-1,1,1)时:
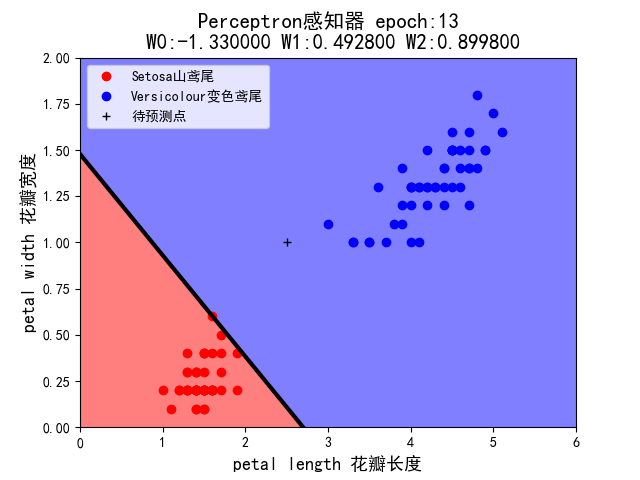
当初始权值设定为(+1,-1,-1)时:
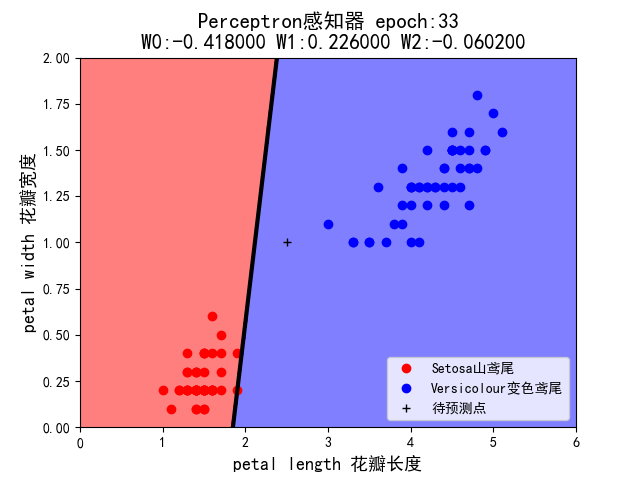
当初始权值设定为(+1,-1,+1) 时:
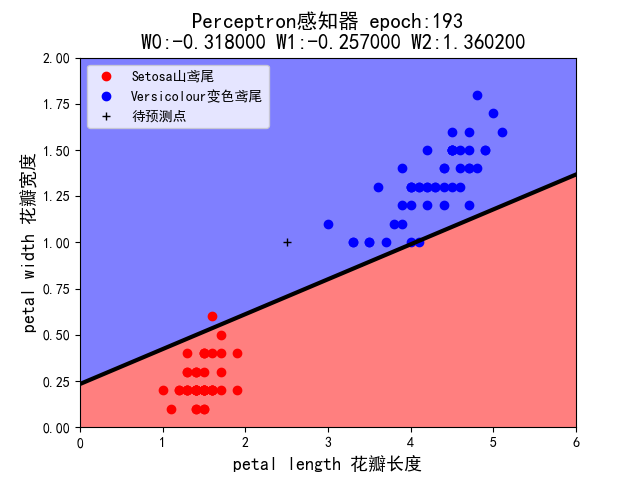
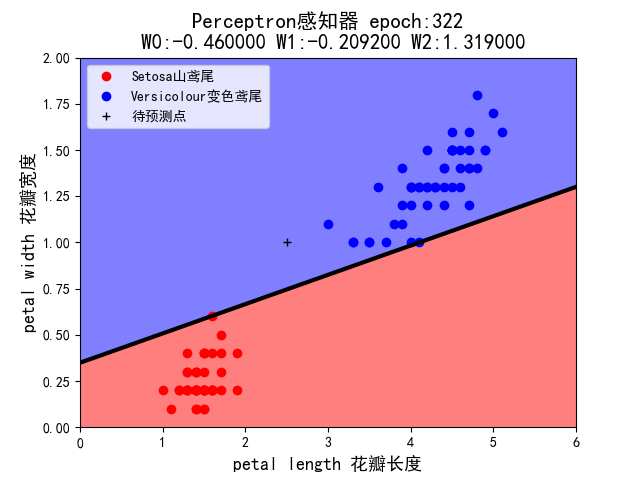
当初始权值设定为(-1,+1,-1) 时:
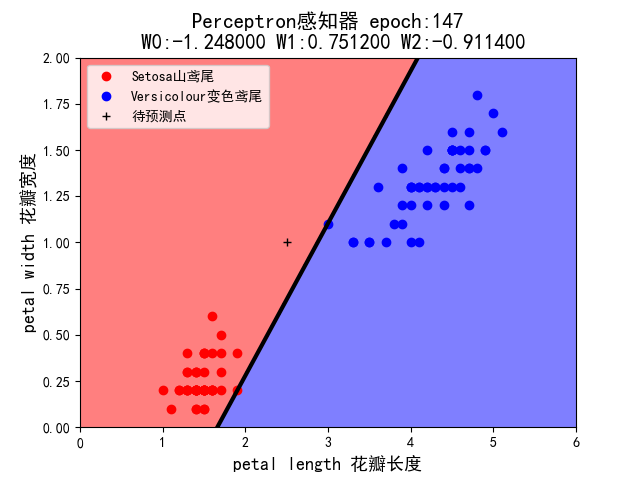
跑程序出现的问题
出问题的前提是在未联网的情况下,跑了感知机实验。
当初始权值设定为(+1,-1,+1) 时,感知机失效,epoch在176-190之间徘徊。与同学对照,发现绝大多数定格在了322次。
- 我尝试重启pycharm,多次尝试后均未奏效。
- 尝试修改程序,先修改学习率跑一次,再把学习率改回来跑,失效。
第三题
3.示例程序使用的是离散感知机还是连续感知机?如何判断?
使用的是离散感知机,因为得到的值不是连续的。
第四题
4.为什么在学习算法中要除以 X.shape[0] ?示例程序采用的是批量下降还是逐一下降?是否属于随机下降?是否属于梯度下降?
由于相加了多次所以要取平均值,保持偏执和其余两项权值大小正常;
属于批量下降
不属于随机下降,不属于梯度下降
X.shape[0]=100
如果不除以X.shape[0]:
[[-100.]
[-146.2]
[-24.6]]
如果除以X.shape[0]:
[[-1]
[-1.426]
[-0.246]]
第五题
5.假设你在自然界找到了一朵鸢尾花,并测得它的花瓣长度为 2.5cm,花瓣宽度为 1cm,它属于哪一类?在 draw()中已用 plt.plot 画出这个’待预测点’。请观察 1~7 这 7 种组合中,感知机的判断始终一致么?这说明它受到什么因素的影响?
- 属于Versicolour 变色鸢尾。
- 暂时空着
- 感知机的判断并不一致,它受到学习率和权值的影响。
第六题
6.修改示例代码,将变色鸢尾的数据替换为维吉尼亚鸢尾,再进行分类。即横轴为花瓣长度,纵轴为花瓣宽度,数据为 Setosa 山鸢尾+Virginica 维吉尼亚鸢尾。
更改代码如下:
1 | |
1 | |
效果:
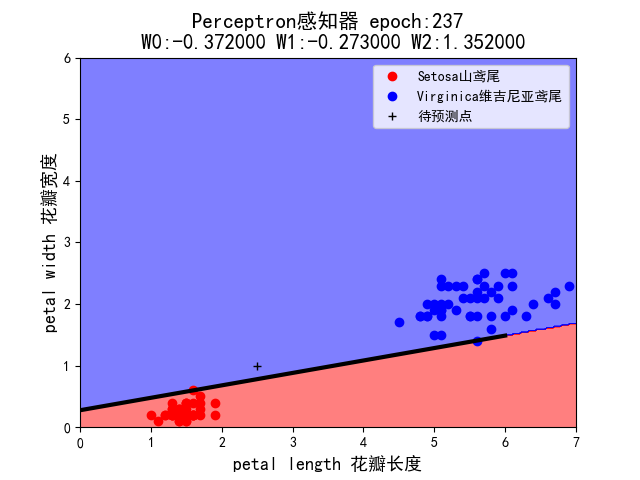
第七题
7.【可选】目前感知机只有两个输入+偏置,如果有三个输入(比如增加萼片长度作为输入),程序应如何修改(可以不画图)?
1 | |
1 | |
完整实验代码
1 | |

