写在前面 今天改bug改到早晨六点,然后九点多睡觉,睡到下午三点,起来等了一个小时,点了一份外卖,南北故事的韭菜炒猪肝还有四季豆炒肉。吃完,投了几份简历,然后出去逛了逛,看到有招聘,索性去了一教502,参加BYD线下宣讲会,到了才发现,他改到了503.我以为有现场面试,没想到依然是先网申,然后明天简历筛选,后天就能面试了。回来,去了一趟酒吧,本想着喝口酒就醉了,有个规律作息,没想到点了个无醇酒,一瓶18rmb,还寻思今天攒攒钱,也没攒下来。回到家,老王说帮我弄一下这个项目,结果我俩都在python这一块折了,老王劝我用scala试一下,如果这个还不行,就用老杨的服务器跑,毕竟配置花了太多时间了。
Spark Streaming实时处理数据(python版本) 编程思想 本案例在于实时统计每秒中男女生购物人数,而Spark Streaming接收的数据为1,1,0,2…,其中0代表女性,1代表男性,所以对于2或者null值,则不考虑。其实通过分析,可以发现这个就是典型的wordcount问题,而且是基于Spark流计算。女生的数量,即为0的个数,男生的数量,即为1的个数。
因此利用Spark Streaming接口reduceByKeyAndWindow,设置窗口大小为1,滑动步长为1,这样统计出的0和1的个数即为每秒男生女生的人数。
编程实现 配置Spark开发Kafka环境 如果之前没有学习过Spark和Kafka的组合使用方法,建议先阅读厦门大学数据库实验室博客文章《Spark2.1.0入门:Apache Kafka作为DStream数据源 》。下面主要介绍配置Spark开发Kafka环境。首先点击下载spark-streaming-kafka ,下载Spark连接Kafka的代码库。
因为我是基于Ubuntu操作,没有图形界面,所以所以使用wget下载。
1 wget https://repo1.maven.org/maven2/org/apache/spark/spark-streaming-kafka-0-10_2.10/2.2.0/spark-streaming-kafka-0-10_2.10-2.2.0.jar
然后把下载的代码库放到目录/usr/local/spark/jars目录下,命令如下:
录/usr/local/spark/jars目录下,命令如下:
1 sudo mv ~/spark-streaming-kafka-0-10_2.10-2.2.0.jar /usr/local/spark/jars
然后在/usr/local/spark/jars目录下新建kafka目录,把/usr/local/kafka/libs下所有函数库复制到/usr/local/spark/jars/kafka目录下,命令如下
1 2 3 4 cd /usr/local/spark/jars
然后,修改 Spark 配置文件,命令如下
1 2 cd /usr/local/spark/conf
把 Kafka 相关 jar 包的路径信息增加到 spark-env.sh,修改后的 spark-env.sh 类似如下:
1 export SPARK_DIST_CLASSPATH=$( /usr/local/hadoop/bin/hadoopclasspath):/usr/local/spark/jars/kafka/* :/usr/local/kafka/libs/*
因为我使用的python3版本,而spark默认使用的是python2,所以介绍一下,怎么为spark设置python环境。
1 export PYSPARK_PYTHON =/usr/bin/python3.6
这里的python3.6是我本地的使用版本,读者在自己实验的时候,要找到你自己本地的版本,这个是一个有点类似exe的一个文件。正常来说,python3的版本对于本实验都可以运行。
1 # Determine the Python executable to use for the executors:if [[ -z "$PYSPARK_PYTHON " ]]; then if [[ $PYSPARK_DRIVER_PYTHON == *ipython* && ! $WORKS_WITH_IPYTHON ]]; then echo "IPython requires Python 2.7+; please install python2.7 or set PYSPARK_PYTHON" 1>&2 exit 1 else PYSPARK_PYTHON=python fifiexport PYSPARK_PYTHON
把上面的 PYSPARK_PYTHON=python改成 PYSPARK_PYTHON=python3.6。
建立Spark项目 首先在/usr/local/spark/mycode新建项目目录
1 2 cd /usr/local/spark/mycode
然后在kafka目录下新建scala文件存放目录以及scala工程文件
1 2 cd kafka
接着在src/main/scala文件下创建两个文件,一个是用于设置日志,一个是项目工程主文件,设置日志文件为StreamingExamples.scala
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package org.apache.spark.examples.streamingimport org.apache.spark.internal.Loggingimport org.apache.log4j.{Level, Logger}for Spark Streaming examples. */object StreamingExamples extends Logging {for streaming if the user has not configured log4j. */if (!log4jInitialized) {'s default logging, then we override the // logging level. logInfo("Setting log level to [WARN] for streaming example." + " To override add a custom log4j.properties to the classpath.") Logger.getRootLogger.setLevel(Level.WARN) } } }
这个文件不做过多解释,因为这只是一个辅助文件,下面着重介绍工程主文件,文件名为KafkaTest.scala
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 package org.apache.spark.examples.streaming
上述代码注释已经也很清楚了,下面在简要说明下:
首先按每秒的频率读取Kafka消息;
然后对每秒的数据执行wordcount算法,统计出0的个数,1的个数,2的个数;
最后将上述结果封装成json发送给Kafka。
另外,需要注意,上面代码中有一行如下代码:
这行代码表示把检查点文件写入分布式文件系统HDFS,所以一定要事先启动Hadoop。如果没有启动Hadoop,则后面运行时会出现“拒绝连接”的错误提示。如果你还没有启动Hadoop,则可以现在在Ubuntu终端中,使用如下Shell命令启动Hadoop:
1 2 cd /opt/hadoop
另外,如果不想把检查点写入HDFS,而是直接把检查点写入本地磁盘文件(这样就不用启动Hadoop),则可以对ssc.checkpoint()方法中的文件路径进行指定,比如下面这个例子:
1 ssc.checkpoint ("file:///usr/local/spark/mycode/kafka/checkpoint")
运行项目 编写好程序之后,接下来编写运行脚本,在/usr/local/spark/mycode/kafka目录下新建simple.sbt,输入如下内容:
1 2 3 4 5 6 7 name := "Simple Project"
然后,即可编译打包程序,输入如下命令
1 /opt/scala/sbt/sbt package
打包成功之后,接下来编写运行脚本,在/usr/local/spark/mycode/kafka目录下新建startup.sh文件,输入如下内容:
1 /usr/local/spark/bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /usr/local/spark/mycode/kafka/target/scala-2.11/simple-project_2.11-1.0.jar 127.0.0.1:2181 1 sex 1
其中最后四个为输入参数,含义如下
127.0.0.1:2181为Zookeeper地址
1 为consumer group标签
sex为消费者接收的topic
1 为消费者线程数
最后在/usr/local/spark/mycode/kafka目录下,运行如下命令即可执行刚编写好的Spark Streaming程序
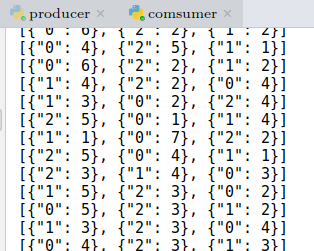
测试程序 下面开启之前编写的KafkaProducer投递消息,然后将KafkaConsumer中接收的topic改为result,验证是否能接收topic为result的消息,更改之后的KafkaConsumer为
1 2 3 4 5 from kafka import KafkaConsumer'result' )for msg in consumer:'utf8' ))
Python
在同时开启Spark Streaming项目,KafkaProducer以及KafkaConsumer之后,可以在KafkaConsumer运行窗口看到如下输出:
到此为止,Spark Streaming程序编写完成,下篇文章将分析如何处理得到的最终结果。