
大数据分析项目之搭建云服务器环境
写在前面
本文基于阿里云ECS服务器撰写。
Ubuntu 18.04
JDK 1.8.0_41
Hadoop 2.10.2
Spark 3.3.0
一些配置
服务器已经配好了ssh,可以通过windows的cmd操作。
终端中输入命令ssh -V。
1 | |
如果显示SSH版本则表示已安装,如下图所示。

b. 如果未安装,请下载安装OpenSSH工具。
在终端中输入连接命令ssh root@[ipaddress]。
将其中的 ipaddress 替换为您的ECS服务器的公网IP地址。例如。
1 | |
命令显示结果如下。
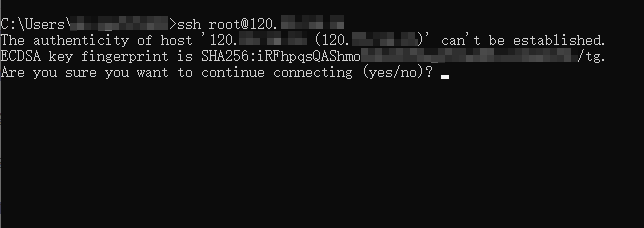
输入 yes,然后输入云服务器的登录密码。(xxxxxxxxxxxxxx)

登录成功后会显示如下信息。

这样就可以操作服务器了。
问题与解决
如果遇到ssh登录远程主机报错:Someone could be eavesdropping on you right now (man-in-the-middle attack)!

会出现这些信息是因为,第一次SSH连接时,会生成一个认证,储存在客户端(也就是用SSH连线其他电脑的那个,自己操作的那个)中的known_hosts,但是如果服务器验证过了,认证资讯当然也会更改,服务器端与客户端不同时,就会跳出错误啦~因此,只要把电脑中的认证资讯删除,连线时重新生成,就一切完美啦~要删除很简单,只要在客户端输入一个指令
ssh-keygen -R 39.108.78.4
接下來再次连接一次,會出現
1 | |
输入yes,
就完成连接啦!同時,新的认证也生成了。
实际操作
服务器的配置
图形界面的安装(没啥用,不用看)
进入页面,选择远程连接。

选择其一进行登录

执行以下命令,更新软件源。
1
apt-get update依次执行以下命令,安装GNOME桌面环境。
1
2apt-get install x-window-system-core
apt-get install gnome-core执行以下命令,启动图形化桌面。
1
startx
HUya00
vnc密码
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server:
1 | |
Shell 命令
安装后,可以使用如下命令登陆本机:
1 | |
Shell 命令
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。
 SSH首次登陆提示
SSH首次登陆提示
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
1 | |

此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
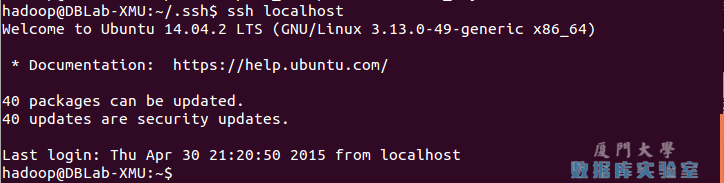 SSH无密码登录
SSH无密码登录
JDK的安装
方式一
因为服务器配置不行,用图形界面太卡了,所以直接用shell操作了。因为实验指南是安装的JDK1.8(即JDK8),所以我们也安装JDK8.
Java 8,前一个 Java LTS 版本,目前仍被广泛应用。如果你的应用运行在 Java 8 上,你可以通过输入下面的命令,安装它:
1 | |
通过检查 Java 版本,来验证安装过程:
1 | |
输出将会像下面这样:
1 | |
安装时的意外与解决
在我安装jdk时候出了一些意外,apt安装还没结束,我就强制退出了,于是出现了Could not get lock /var/lib/dpkg/lock-frontend. It is held by process 20758 (apt)这种情况。
运行下面的命令来生成所有含有 apt 的进程列表,你可以使用ps和grep命令并用管道组合来得到含有apt或者apt-get的进程。
1 | |
找出所有的 apt 以及 apt-get 进程
1 | |
这样操作就可以了。
JAVA_HOME 环境变量配置
在一些 Java 应用中,环境变量JAVA_HOME被用来表示 Java 安装位置。
想要设置 JAVA_HOME 变量,首先使用update-alternatives找到 Java 安装路径:
1 | |
在这个例子中,安装路径如下:
- OpenJDK 8 is located at
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
一旦你发现你偏好的 Java 安装路径,打开/etc/environment文件:
1 | |
假设你想设置 JAVA_HOME 指定到 OpenJDK 8,在文件的末尾,添加下面的行:
1 | |
想要让修改在当前 shell 生效,你可以登出系统,再登入系统,或者运行下面的命令:
1 | |
验证 JAVA_HOME 环境变量被正确设置:
1 | |
你应该可以看到 Java 安装路径:
1 | |
方式二
- 执行以下命令,下载JDK1.8安装包。
1 | |
- 执行以下命令,解压下载的JDK1.8安装包。
1 | |
- 执行以下命令,移动并重命名JDK包。
1 | |
- 执行以下命令,配置Java环境变量。
1 | |
- 执行以下命令,查看Java是否成功安装。
1 | |
如果返回以下信息,则表示安装成功。

安装 Hadoop
2022.9.4
下载Hadoop安装包,要利用firefox。而我运行 firefox命令时却遇到了xdg-settings: not found错误。
按照提示,输入命令 sudo apt-get install xdg-utils安装xdg-utils。
安装好后,又出现 no DISPLAY environment variable specified错误。
我以为是图形界面的问题,于是查找解决方案,用 sudo apt-get install ubuntu-desktop -y命令安装图形桌面。
每次安装完软件后都会出现这种:

也就是上面JDK安装时遇到的意外。
解决方法在StackOverFlow找到:
如果您不想收到此类消息,请通过以下方式删除此应用程序
1 | |
捣鼓了半天,看到:这里要注意!!!控制台提供的远程连接中workbench好像是不能使用图形化界面的,要切换到vnc
我是用远程连接中workbench登陆的,这回我用vnc尝试登陆一下。
vnc登录没有反应,我决定重启电脑。
hexo推送这个时候也出现了问题,累了,先不搞了。
2022.9.5
我发现不用firefox也可以安装hadoop,需要切换到root用户,输入
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz命令,便可下载hadoop安装包。执行以下命令,解压Hadoop安装包至 /opt/hadoop。
1
2
3
4
5
6
7tar -zxvf hadoop-2.10.2.tar.gz -C /opt/
mv /opt/hadoop-2.10.2 /opt/hadoop
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile执行以下命令,修改配置文件yarn-env.sh 和 hadoop-env.sh。
1
2echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh安装成功的样子

配置Hadoop
修改Hadoop配置文件core-site.xml。
a. 执行以下命令开始进入编辑页面。
1 | |
b. 输入 i 进入编辑模式。
c. 在
1 | |
d. 按Esc键退出编辑模式,输入:wq保存退出。
修改Hadoop配置文件 hdfs-site.xml。
a. 执行以下命令开始进入编辑页面。
1 | |
b. 输入 i 进入编辑模式。
c. 在
1 | |
d. 按Esc键退出编辑模式,输入:wq保存退出。
启动Hadoop
键入命令 source /etc/profile使hadoop的相关配置生效
- 执行以下命令,初始化namenode 。
1 | |
- 依次执行以下命令,启动Hadoop。
1 | |
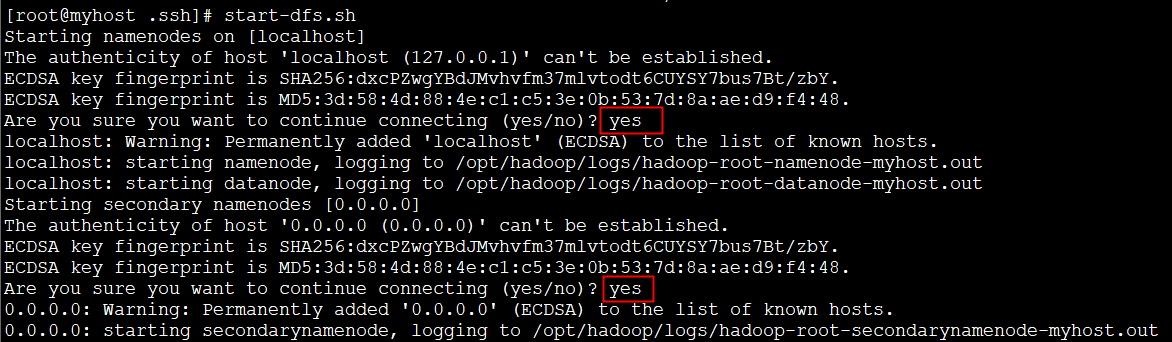
1 | |

- 启动成功后,执行以下命令,查看已成功启动的进程。
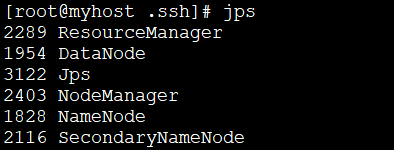
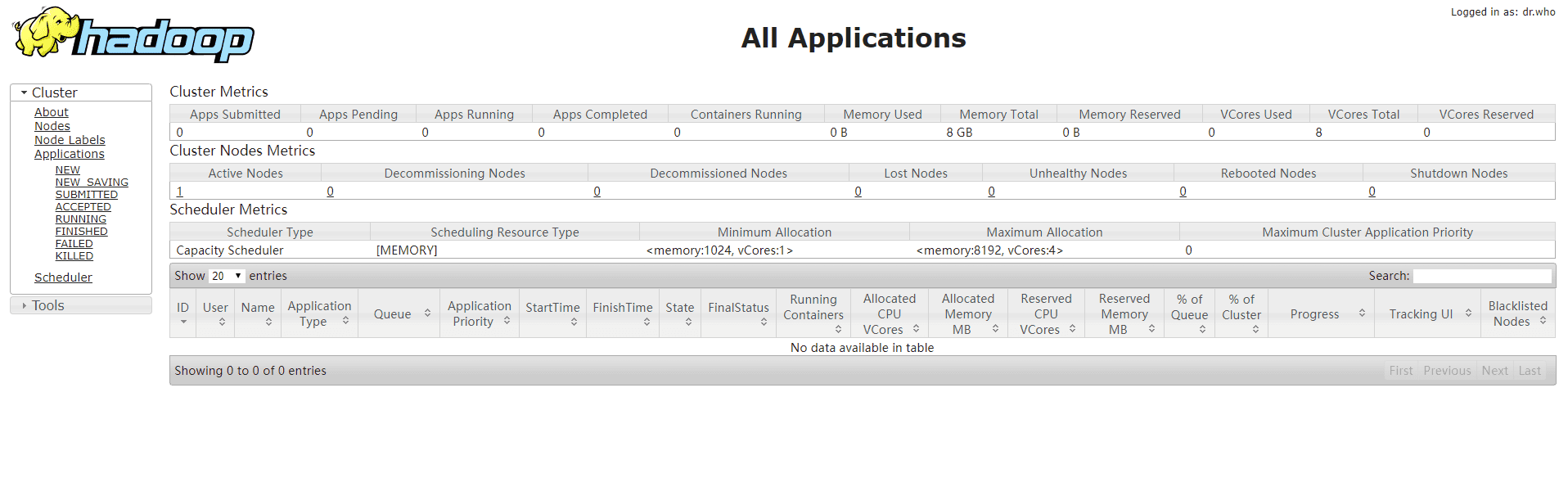
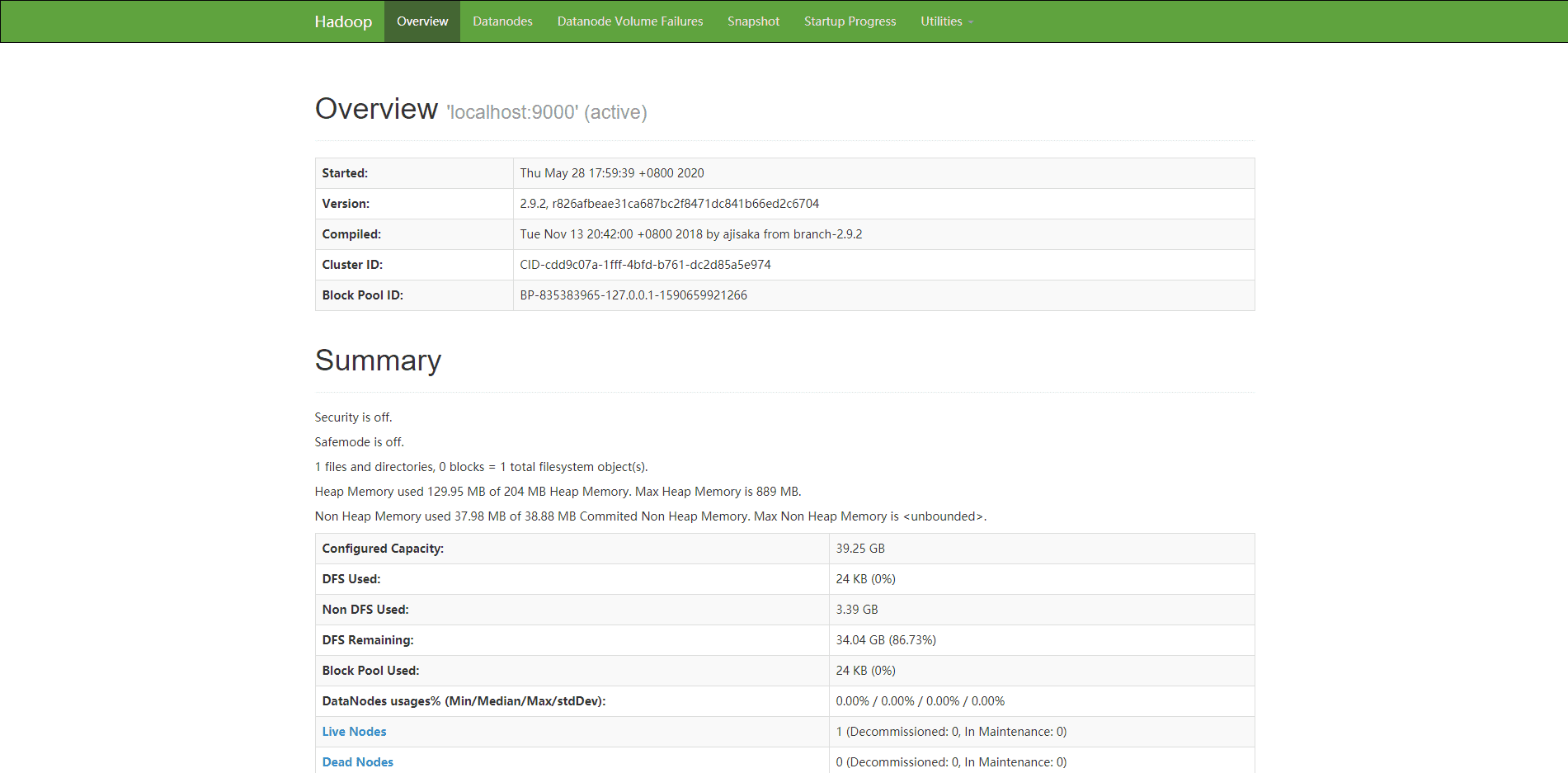
- 打开浏览器访问http://<ECS公网IP>:8088 和 http://<ECS公网IP>:50070,显示如下界面则表示Hadoop伪分布式环境搭建完成。
遇到的问题与解决方案(Hadoop 3.x版本)
启动Hadoop时,输入start-dfs.sh命令,输出如下结果:

这是Hadoop 3.x版本的坑。我是在root用户下配置的。所以要增添一些东西。
在/opt/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数1
2
3
4HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root start-yarn.sh,stop-yarn.sh顶部也需添加以下
1
2
3YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root在启动start-dfs.sh时又碰到了WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.错误。
解决方案,在$ vim sbin/start-dfs.sh $ vim sbin/stop-dfs.sh 将
HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
改为HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
按提示解决方案1与解决方案2通过rm -rf删除文件,结果操作不当,将系统搞坏了,所以我现在要重装系统。

Spark的安装
输入命令 wget https://dlcdn.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-without-hadoop.tgz或wget https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0-bin-without-hadoop.tgz
接着输入 sudo tar -zxvf spark-3.3.0-bin-without-hadoop.tgz.1 -C /usr/local/或者
sudo tar -zxvf spark-2.2.0-bin-without-hadoop.tgz -C /usr/local/
解压后,找到文件cd /usr/local
将文件转移到另一个文件夹,sudo mv ./spark-3.3.0-bin-without-hadoop/ ./spark或者sudo mv ./spark-2.2.0-bin-without-hadoop/ ./spark
紧接着 sudo chown -R root:root ./spark # 此处的 root 为你的用户名
安装后,还需要修改Spark的配置文件spark-env.sh
1 | |
编辑spark-env.sh文件(vim ./conf/spark-env.sh),在第一行添加以下配置信息:
1 | |
有了上面的配置信息以后,Spark就可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
配置完成后就可以直接使用,不需要像Hadoop运行启动命令。
通过运行Spark自带的示例,验证Spark是否安装成功。
1 | |
执行时会输出非常多的运行信息,输出结果不容易找到,可以通过 grep 命令进行过滤(命令中的 2>&1 可以将所有的信息都输出到 stdout 中,否则由于输出日志的性质,还是会输出到屏幕中):
1 | |

Kafka的安装(错误版)
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
Kafka的使用依赖于zookeeper,安装Kafka前必须先安装zookeeper.
键入命令 cd ~/ 进入home文件夹,访问Kafka官方下载页面,拿到下载路径,输入
wget https://downloads.apache.org/kafka/3.2.1/kafka-3.2.1-src.tgz下载安装包
1 | |
发生的问题
进行简单实例测试时,遇到了Classpath is empty. Please build the project first e.g. by running ‘./gradlew jar -PscalaVersion=2.13.6’错误。
发现从官网下的是源码。。。
不要下载带src的文件
正确文件名形如:https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.2.1/kafka_2.12-3.2.1.tgz
另 网上其他资料得知 安装路径不得有空格
Kafka安装(正确版)
拿到下载路径,输入
wget https://archive.apache.org/dist/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz下载安装包
1 | |
核心概念
下面介绍Kafka相关概念,以便运行下面实例的同时,更好地理解Kafka.
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为brokerTopic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.Producer
负责发布消息到Kafka brokerConsumer
消息消费者,向Kafka broker读取消息的客户端。Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
测试简单实例
下来在Ubuntu系统环境下测试简单的实例。按顺序执行如下命令:
1 | |
命令执行后不会返回Shell命令输入状态,zookeeper就会按照默认的配置文件启动服务,请千万不要关闭当前终端.启动新的终端,输入如下命令:
1 | |
注意:现在开一个终端,需要手动启动java环境变量 source /etc/profile(JDK安装,方式2)
kafka服务端就启动了,请千万不要关闭当前终端。启动另外一个终端,输入如下命令:
1 | |
执行这条命令时出现了异常
异常与解决

新版本的kafka,已经不需要依赖zookeeper来创建topic,新版的kafka创建topic指令为下:
bin/kafka-topics.sh --create --bootstrap-server iZwz95km8ocqkoc1k5jk6sZ:9092 --replication-factor 1 --partitions 1 --topic test1
注意,这里的master是我主机ip映射的主机名,改成该kafka服务器对应的IP即可。


此时异常解决,我们接着做。
topic是发布消息发布的category,以单节点的配置创建了一个叫dblab的topic.可以用list列出所有创建的topics,来查看刚才创建的主题是否存在。
1 | |
Shell 命
可以在结果中查看到dblab这个topic存在。接下来用producer生产点数据:
1 | |
Shell 命令
并尝试输入如下信息:
1 | |
然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
1 | |
Shell 命令
便可以看到刚才产生的三条信息。说明kafka安装成功。

安装Pycharm
我们是基于Ubuntu系统安装的,没有图形桌面系统,那么我们如何用命令进行操作呢?
首先按照官网的提示,

我们可以使用snap命令进行安装。
在安装Pycharm之前,我们要先安装snap。
You can install it with the command below:
1 | |
输入命令sudo snap install pycharm-community --classic安装pycharm。

使用Pycharm
因为服务器没有图形界面,所以我们用Pycharm同步本地与服务器代码。
详见这篇文章:用Pycharm同步本地与服务器代码.


