
大数据分析项目之Spark Streaming实时处理数据
写在前面
今天投了中建的很多建立,过了中建八局的一测,二测考了61分,希望能如愿进入面试。
Spark Streaming实时处理数据(python版本)
编程思想
本案例在于实时统计每秒中男女生购物人数,而Spark Streaming接收的数据为1,1,0,2…,其中0代表女性,1代表男性,所以对于2或者null值,则不考虑。其实通过分析,可以发现这个就是典型的wordcount问题,而且是基于Spark流计算。女生的数量,即为0的个数,男生的数量,即为1的个数。
因此利用Spark Streaming接口reduceByKeyAndWindow,设置窗口大小为1,滑动步长为1,这样统计出的0和1的个数即为每秒男生女生的人数。
编程实现
配置Spark开发Kafka环境
如果之前没有学习过Spark和Kafka的组合使用方法,建议先阅读厦门大学数据库实验室博客文章《Spark2.1.0入门:Apache Kafka作为DStream数据源》。下面主要介绍配置Spark开发Kafka环境。首先点击下载spark-streaming-kafka,下载Spark连接Kafka的代码库。
因为我是基于Ubuntu操作,没有图形界面,所以所以使用wget下载。
1 | |
然后把下载的代码库放到目录/usr/local/spark/jars目录下,命令如下:
录/usr/local/spark/jars目录下,命令如下:
1 | |
然后在/usr/local/spark/jars目录下新建kafka目录,把/usr/local/kafka/libs下所有函数库复制到/usr/local/spark/jars/kafka目录下,命令如下
1 | |
然后,修改 Spark 配置文件,命令如下
1 | |
把 Kafka 相关 jar 包的路径信息增加到 spark-env.sh,修改后的 spark-env.sh 类似如下:
1 | |
因为我使用的python3版本,而spark默认使用的是python2,所以介绍一下,怎么为spark设置python环境。
要改两个地方,一个是conf目录下的spark_env.sh:在这个文件的开头添加:
1 | |
这里的python3.6是我本地的使用版本,读者在自己实验的时候,要找到你自己本地的版本,这个是一个有点类似exe的一个文件。正常来说,python3的版本对于本实验都可以运行。
第二个地方要修改,/usr/local/spark/bin/pyspark这个文件。参照以下修改这个地方:
1 | |
把上面的 PYSPARK_PYTHON=python改成 PYSPARK_PYTHON=python3.6。
这样子就是使用本地的python3.6环境了。
建立pySpark项目
首先在/usr/local/spark/mycode新建项目目录
1 | |
然后在kafka这个目录下创建一个kafka_test.py文件。
touch kafka_test.py
1 | |
Python
上述代码注释已经也很清楚了,下面在简要说明下:
首先按每秒的频率读取Kafka消息;
然后对每秒的数据执行wordcount算法,统计出0的个数,1的个数,2的个数;
最后将上述结果封装成json发送给Kafka。
另外,需要注意,上面代码中有一行如下代码:
1 | |
这行代码表示把检查点文件写入分布式文件系统HDFS,所以一定要事先启动Hadoop。如果没有启动Hadoop,则后面运行时会出现“拒绝连接”的错误提示。如果你还没有启动Hadoop,则可以现在在Ubuntu终端中,使用如下Shell命令启动Hadoop:
1 | |
另外,如果不想把检查点写入HDFS,而是直接把检查点写入本地磁盘文件(这样就不用启动Hadoop),则可以对ssc.checkpoint()方法中的文件路径进行指定,比如下面这个例子:
1 | |
运行项目
编写好程序之后,接下来编写运行脚本,在/usr/local/spark/mycode/kafka目录下新建startup.sh文件,输入如下内容:
1 | |
其中最后四个为输入参数,含义如下
127.0.0.1:2181为Zookeeper地址
1 为consumer group标签
sex为消费者接收的topic
1 为消费者线程数
最后在/usr/local/spark/mycode/kafka目录下,运行如下命令即可执行刚编写好的Spark Streaming程序
1 | |
这个时候出现了错误。

查找发现原因可能是pyspark与spark版本不匹配导致的。直接使用from pyspark.streaming.kafka import KafkaUtils会提示这个错误。
降低版本后又出现错误:

安装对应jar包到/usr/local/lib/python3.6/dist-packages/pyspark/jars/ spark-streaming-kafka-0-8-assembly_2.10-2.2.0.jar。jar.
解决方法1
因为服务器spark版本不一致,所以考虑使用pyspark.streaming.kafka。如链接中博客所言,需要findspark模块。
pip3 install findspark
1 | |
我们对之前的/usr/local/spark/mycode/kafka/kafka_test.py文件进行修改
结果是失败的。
解决方法2
我重新安装了pyspark,版本是3.2.2.我们现在用的spark版本是3.3.0.
后来发现,Kafka 0.10(及更高版本)不支持 Python了。此时我打算用scala试一下。很麻烦,还是研究python把。
我决定对kafka降级。–> 0.10
我决定对spark进行降级。–> 2.2.0
下载对应Jar包到 /usr/local/spark/jars。又出现了如下错误:

程序运行成功之后,下面通过步骤二的KafkaProducer和KafkaConsumer来检测程序。
测试程序
下面开启之前编写的KafkaProducer投递消息,然后将KafkaConsumer中接收的topic改为result,验证是否能接收topic为result的消息,更改之后的KafkaConsumer为
1 | |
Python
在同时开启Spark Streaming项目,KafkaProducer以及KafkaConsumer之后,可以在KafkaConsumer运行窗口看到如下输出: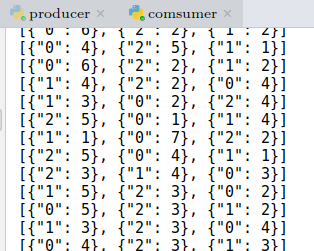
到此为止,Spark Streaming程序编写完成。
