拓荒者
我们身为HNUST第一批数据科学与大数据技术专业的本科生,非常激动能够使用学院提供的服务器集群,并在这里留下属于我们的痕迹。
前置准备工作
CDH环境说明
集群目前是以应用用途来划分hdfs用户,因此没有各位同学专属的目录。为此需要各位同学自行设置环境变量指明当前的hdfs用户,建议使用hdfs作为用户。具体做法为在远程终端登录之后(XSHELL 登录成功之后 ) 中执行如下命令。
1
| export HADOOP_USER_NAME=hdfs
|
或者可以将上述命令添加到自己使用的shell环境变量配置文件,以避免每次都需要重新执行上述命令,默认情况下用户配置文件是指是~/.bashrc。
可以通过 vim 文本处理命令添加。也可以通过下面的命令直接完成。
1
2
| echo "export HADOOP_USER_NAME=hdfs" >> ~/.bashrc
source ~./bashrc
|
在我们指明了当前的用户之后,分布式文件系统的相对目录会对应在分布式文件系统的/user/hdfs 目录下。
准备工作
为了避免各位同学的数据之间有混淆,建议建立一个自己的文件夹,这里以bigdata9为例。请注意自己运行时以自己的账号为文件夹名称,或其他可以与其它同学区别开的文件夹名称。
1
| hadoop fs -mkdir bigdata9
|
之后我们可以使用该目录作为我们使用的目录。
以实验一为例子。
实验一(SHELL版 )
生成实验所需要的数据文件。
1
2
3
4
| for i in {1..5};
do
echo $i$i$i >> input/$i.txt;
done
|
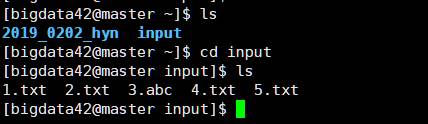
通过这样我们把实验所需的数据生成在了input目录下。
我们可以看到input目录下的文件为
1
2
3
4
5
| 1.txt
2.txt
3.abc
4.txt
5.txt
|
把input目录上传到我们先前准备的文件目录
1
| hadoop fs -put input bigdata9
|
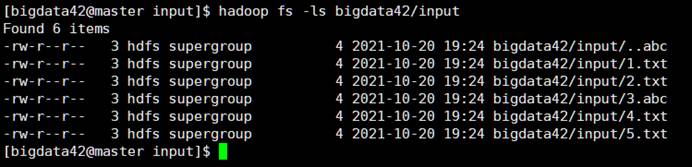
运行如下命令可以查看我们的在 HDFS下的文件
1
| hadoop fs -ls bigdata9/input
|
对于实验一我们可以通过如下一行命令完成
1
| hadoop fs -ls bigdata9/input | awk '{print $8}'| sed -e '1d'|grep -v ".abc$"|xargs hadoop fs -cat
|
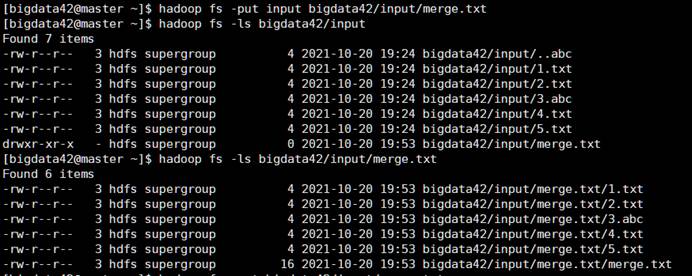
可以看到输出中没有以abc为后缀名的文件内容 (333),如果需要将输出内容全部保存,则可以通过使用输出重定向完成。也就是在上述命令的末尾添加 >> merge.txt 完成输出的保存。需要注意的是这样文件会被保存在当前本地目录下。
实验一
实验环境:
(1)IDE:idea
(2)Hadoop版本:3.1.0
(3)辅助工具:big data tools
(本次实验为分布式环境下HDFS编程实例)
任务描述:
假设在HDFS下有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc、file5.abc,这里需要从目录中过滤出所有后缀不为.abc的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件merge.txt中。
实验步骤:
一、Shell版
二、JavaAPI版:
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| package com.van;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
public class Hadoop_practice01 {
private FileSystem fs;
Path workDir;
Path resultFile;
Configuration conf ;
@Before
public void Init() throws URISyntaxException, IOException, InterruptedException {
URI uri = new URI("hdfs://125.221.232.243:8020");
String user = "hdfs";
conf = new Configuration();
fs = FileSystem.get(uri, conf,user);
}
@After
public void close() throws IOException {
fs.close();
}
@Test
public void testmkdir() throws URISyntaxException, IOException, InterruptedException {
fs.mkdirs(new Path("bigdata82/Practice01"));
}
@Test
public void testMerge() throws IOException {
workDir = new Path("bigdata82/Practice01");
resultFile = new Path(workDir, "merge.txt");
Path[] paths = Arrays.stream(fs.listStatus(workDir, path -> !path.toString().matches("[\\s\\S]*?\\.abc")) ).map(FileStatus::getPath).toArray(Path[]::new);
fs.createNewFile(resultFile);
fs.concat(resultFile, paths);
InputStream resultFile= fs.open(this.resultFile);
System.out.println("合并后的 merge.txt 内容");
IOUtils.copyBytes(resultFile, System.out, conf);
}
}
|
实验效果:
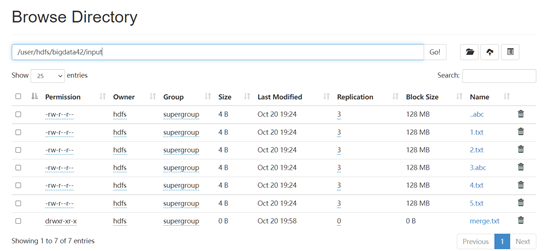
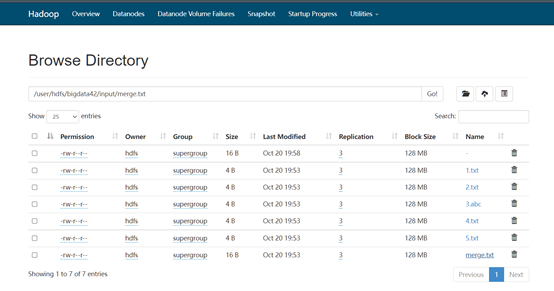
实验七
实验环境:
(1)IDE:idea
(2)Hadoop版本:3.1.0
(3)辅助工具:big data tools
实验生成测试数据代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import random
"""
Author: HuYaNING
Date: 2021.10.23 18:41
"""
txtName = "Generate_data04.txt"
txtLine = 188
pid = ["01","02","03","04","05","06","07","08","09","10"]
i = 1;
f = open(txtName,'w',encoding="utf-8")
while(i<=txtLine):
f.write(str(1000+i)+" "+pid[random.randint(0,9)]+" "+str(i)+"\n")
i = i+1
f.close()
|
实验指导:
创建了文件夹:
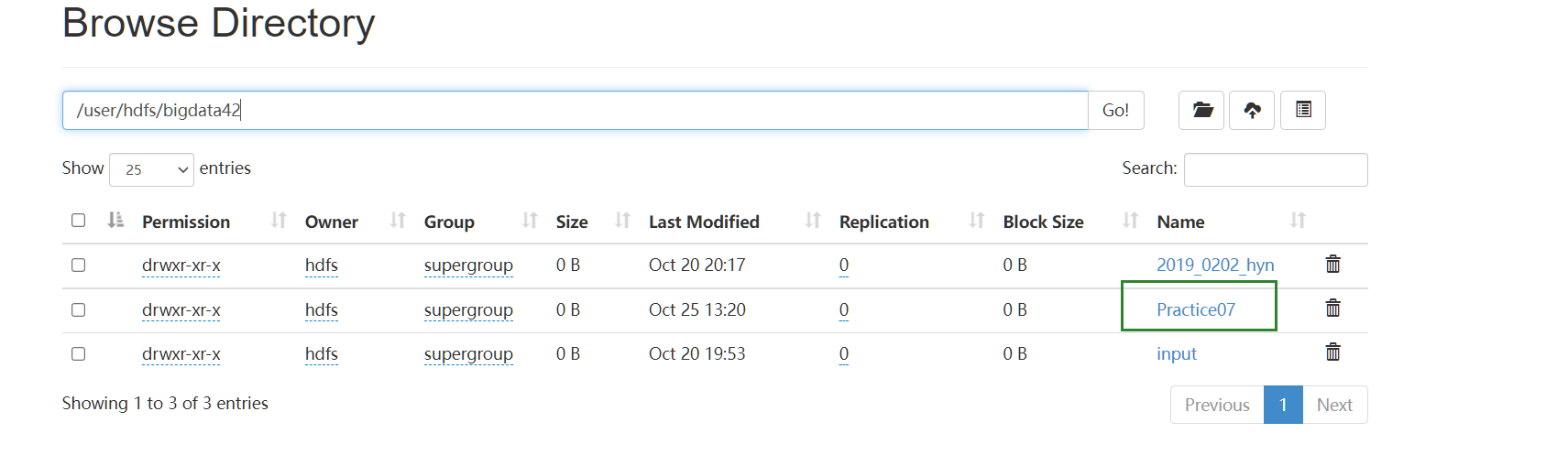
在从终端上传文件到远端时出错:
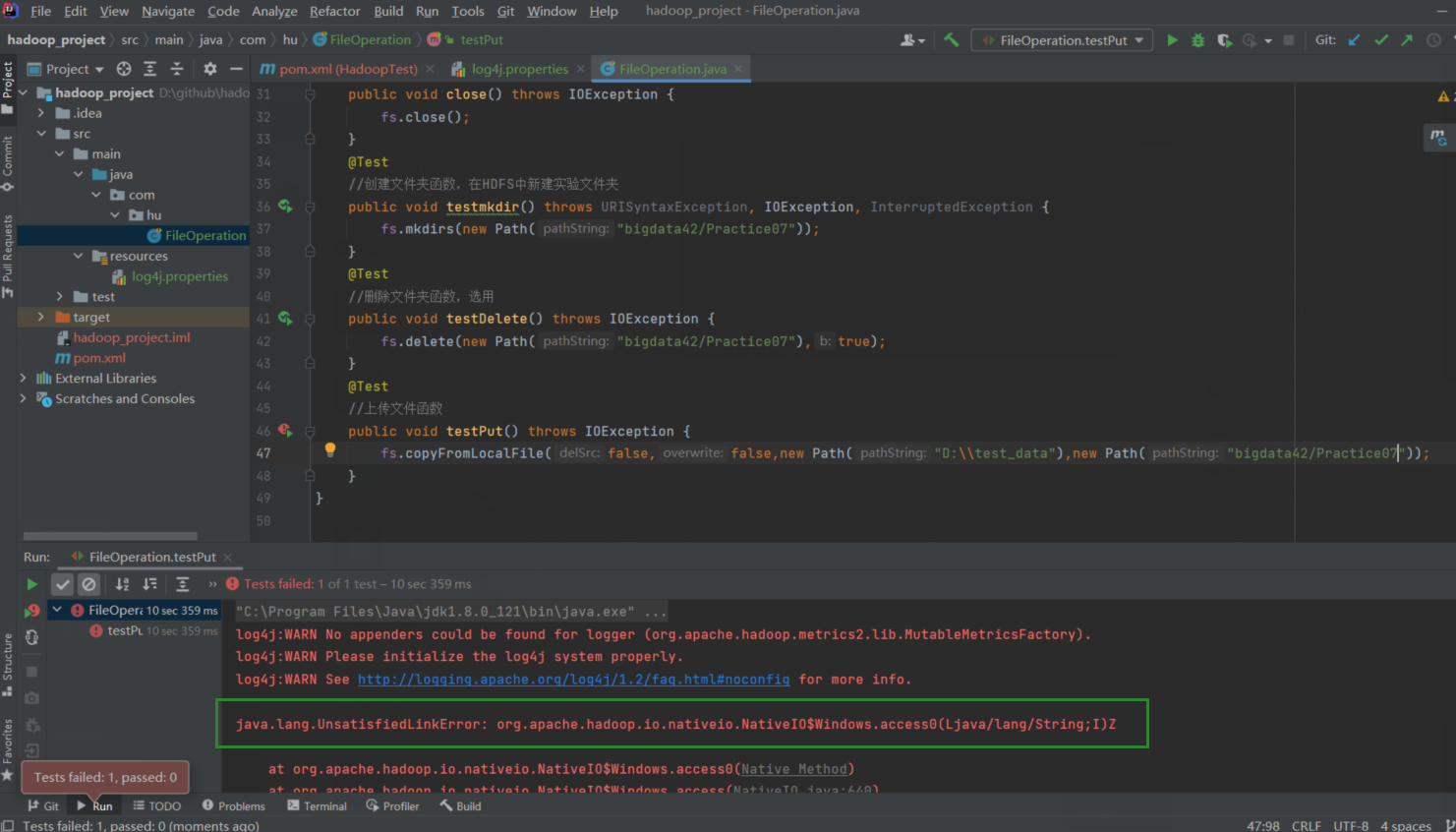
原因:windows下没有hadoop的环境变量,需要安装Hadoop解决。


