
python与数据分析题库
第一章 Python与数据分析
一、选择题
- 数据分析第三方库包括( A B C )
A. NumPy B. Matplotlib C. Pandas D. Pygame
- 不是数据分析常用工具的是( B )
A. Python B. Java C. MATLAB D. R
二、填空题
数据分析流程包括: 需求分析、数据获取、数据预处理、分析与建模、模型评价与优化、部署 等环节。
广义的数据分析包括 狭义数据分析 、 数据挖掘 两部分。
三、简单题
- Python数据分析的优势。
答:1. 语法简单精炼。比起其他编程语言,Python更容易学习和使用。
功能强大的库。大量优秀好用的第三方库,扩充了Python功能,提升了Python的能力,使Python如虎添翼。
功能强大。Python是一个混合体,丰富的工具使它介于传统的脚本语言和系统语言之间。Python不仅具备简单易用的特点,还提供了编译语言所具有的软件工程能力。
不仅适用于研究和原型构建,同时也适用于构建生产系统。研究人员和工程技术人员使用同一种编程工具,会给企业带来显著的组织效益,并降低企业的运营成本。
Python是一门胶水语言。Python程序能够以多种方式轻易地与其他语言的组件“粘接”在一起,例如Python的C语言API可以帮助Python程序灵活地调用C程序。因此可以根据需要给Python程序添加功能,或者其他环境系统中使用Python。
Python数据分析环境搭建。
答:1. 安装Python
- 安装数据分析库
(1)安装第三方数据分析库
第三方库的安装使用pip3命令,如下所示。
pip3 install numpy
pip3 install scipy
pip3 install matplotlib
pip3 install sklearn
pip3 install xlrd
pip3 install openpyxl
pip3 install seaborn
- Jupyter Notebook的使用
Jupyter Notebook是IPython Notebook的继承者,是一个交互式笔记本,支持运行40多种编程语言。它本质上是一个支持实施代码、数学方程、可视化和Markdown的Web应用程序。对于数据分析,Jupyter Notebook最大的优点是可以重现整个分析过程,并将说明文字、代码、图表、公式和结论都整合在一个文档中。用户可以通过电子邮件、Dropbox、GitHub和Jupyter Notebook Viewer将分析结果分享给其他人。
Jupyter Notebook是一个非常强大的工具,常用于交互式地开发和展示数据科学项目。它将代码和它的输出集成到一个文档中,并且结合了可视的叙述性文本、数学方程和其他丰富的媒体。它直观的工作流促进了迭代和快速的开发,使得Jypyter notebook 在当代数据科学、分析和越来越多的科学研究中越来越受欢迎。最重要的是,作为开源项目,它是完全免费的。
第二章 NumPy数值计算
一、单选题
不是NumPy数组创建的函数是( D )。
A. array B. ones_like C. eye D. reshape
能够产生正态分布的样本值的函数是( C )。
A. rand B. randint C. randn D. seed
求数组转置的除了使用transpose函数外,还可以使用数据的( A )属性。
A. T B. shape C. size D. dtype
二、填空题
分割数组的函数有 split 、 hsplit 、 vsplit 。
求数组的标准差函数是 std ,方差函数是 var 。
求矩阵特征值和特征向量的函数是 eigvals() 、 eig() 。
三、简答题
- 函数unique的参数。
答:
参数arr:输入数组,如果不是一维数组则会展开。
return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储。
return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储。
return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数。
- 数组可以广播的条件。
答:
数组拥有相同形状。
数组拥有相同的维数,每个维度拥有相同长度,或者长度为 1。
数组拥有极少的维度,可以在其前面追加长度为 1 的维度,使上述条件成立。
函数sort的排序算法。
答:
| 种类 | 排序算法 | 最坏情况 |
|---|---|---|
| ‘quicksort’ | 快速排序 | O(n^2) |
| ‘mergesort’ | 归并排序 | O(n*log(n)) |
| ‘heapsort’ | 堆排序 | O(n*log(n)) |
四、读程序
- 程序执行结果是 。

import numpy as np
a = np.arange(12).reshape(2,6)
c = a.ravel()
c[0]=100
print(a)
- 程序执行结果是 。

import numpy as np
a = np.arange(9)
b = np.split(a,3)
print (b)
- 程序执行结果是 。

import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print(np.append(a, [7,8,9]))
print(np.append(a, [[7,8,9]],axis = 0))
print(np.append(a, [[5,5,5],[7,8,9]],axis = 1))
- 程序执行结果是 。

import numpy as np
a = np.array([5,2,6,2,7,5,6,8,2,9])
u = np.unique(a)
u,indices = np.unique(a, return_index = True)
print(indices)
u,indices = np.unique(a,return_inverse = True)
print(u)
print(indices)
print(u[indices])
u,indices = np.unique(a,return_counts = True)
print(u)
print(indices)
- 程序执行结果是 。

import numpy as np
a = np.array([10,100,1000])
print(np.power(a,2))
b = np.array([1,2,3])
print(np.power(a,b))
- 程序执行结果是
 。
。
import numpy as np
a = np.array([[3,7],[9,1]])
print(np.sort(a))
print(np.sort(a, axis = 0))
dt = np.dtype([(‘name’, ‘S10’),(‘age’, int)])
a = np.array([(“raju”,21),(“anil”,25),(“ravi”, 17), (“amar”,27)], dtype = dt)
print(np.sort(a, order = ‘name’))
- 程序执行结果是 。

import numpy as np
x = np.arange(100).reshape(10, 10)
condition = np.mod(x,2) == 0
print(np.extract(condition, x))
五、计算题
1.计算下列行列式
(1)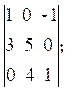 =
= 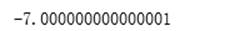
- 求下列方阵的逆矩阵
(1)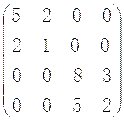 =
= 
(2) =
= 
- 求下列线性方程组
(1)设 ,
, ,求X使AX=B;
,求X使AX=B;
(2)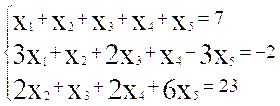 无法求解。
无法求解。
- 求矩阵的特征值和特征向量。
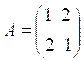

第三章 Matplotlib数据可视化
一、选择题
- 线形图中设置线宽的函数是( C )
A. color B. linestyle C. linewidth D. marker
- 显示一个数据系列中各项的大小与各项总和的比例的图形时( A )
A. 饼图 B. 直方图 C.柱形图 D. 散点图
- 图例位置upper left对应的编号是( A )
A. 0 B. 1 C. 2 D. 3
二、填空题
绘制饼图的函数是 pie() 。
pyplot设置x坐标取值范围的函数是 xlim 。
pyplot使用rcParams设置字体的属性是 font.sans-serif 。
三、简答题
- 创建子图的函数。
答:
subplot函数
函数subplot (nrows, ncols, plot_number)创建子图,其中参数nrows,ncols表示行数和列数,决定了子图的个数;plot_number表示当前是第几个子图。
subplots函数
函数plt.subplots(nrows=1, ncols=1, sharex=False, sharey=False, squeeze=True, subplot_kw=None, gridspec_kw=None,**fig_kw)
参数nrows和ncols表示将画布分割成几行几列。
sharex和sharey表示坐标轴的属性是否相同。
- Matplotlib能够绘制哪些二维图形。
答:折线图、散点图、柱状图、条形图、饼图、直方图、线形图等。
- 文本注解函数。
答:
(1)在任意位置增加文本
plt.text(横坐标, 纵坐标, ‘显示文字’)
(2)在图形中增加带箭头的注
plt.annotate(‘文字’,xy=(箭头坐标),xytext=(文字坐标),arrowprops=dict(facecolor=’箭头颜色’))
第四章 Pandas数据分析
一、选择题
- 函数应用与映射函数作用于DataFrame的列的是( A )
A pipe B apply C applymap D map
- 重建索引函数( D )
A. rename B. set_index C. reset_index D. reindex
- 求协方差的函数是( B )
A. pct_change B. corr C. rank D. cov
二、填空题
数据对象DataFrame的head函数的作用是 返回开头前n行 。
函数read_csv的参数sep的作用是指定 分隔符 。
数据对象DataFrame选取行的函数主要是loc函数和 iloc 函数。
透视表和交叉表的函数是 pivot_table 和 crosstab 。
三、简答题
- Pandas有哪些数据结构。
答:Pandas有三种数据结构:系列(Series)、数据帧(DataFrame)和面板(Panel),这些数据结构可以构建在NumPy数组之上。
- Pandas的统计函数。
答:
| 函数 | 描述 |
|---|---|
| count() | 非空观测数量 |
| sum() | 所有值之和 |
| mean() | 所有值的平均值 |
| median() | 所有值的中位数 |
| mode() | 值的模值 |
| std() | 值的标准偏差 |
| min() | 所有值中的最小值 |
| max() | 所有值中的最大值 |
| abs() | 绝对值 |
| prod() | 数组元素的乘积 |
| cumsum() | 累计总和 |
| cumprod() | 累计乘积 |
| describe | 计算有关DataFrame列的统计信息的摘要 |
变化率使用pct_change()函数求解,系列和DatFrames都可以通过pct_change()函数将每个元素与其前一个元素进行比较,并计算变化百分比。
Panda使用cov函数求解两个Series或DataFrame的列之间的协方差。如果数据对象中出现NaN数据,将被自动排除。
相关性DataFrame.corr(method=’pearson’, min_periods=1)
数据排名为元素数组中的每个元素生成排名,使用rank函数实现,其参数axis表示按照index(默认axis=0)还是按照column(axis=1)排名,参数methon表示排名依据:average(并列组平均排序等级)、min(组中最低的排序等级)、max(组中最高的排序等级)、first(按照它们出现在数组中的顺序分配队列)。
- 聚合函数有哪些。
答:
- agg方法聚合
方法agg是比较常用的聚合方法,agg的参数可以是一个函数,也可以是多个函数组成的列表。
apply方法聚合
transform方法聚合
第五章 数据预处理
一、选择题
- 重复值删除的函数是( A )
A. drop_duplicates B. duplicated C. isnull D. notnull
- 不是数据规范化方法的是( D )
A. 离差规范化 B. 标准差规范化 C. 小数定标规范化 D. 平均值规范化
- 数据重塑方法有( D )
A. dropna B. fillna C. stack D. concat
二、填空题
数据清洗解决数据问题有 重复值 、 缺失值 、 异常值 。
虚拟变量的函数名称是 get_dummies 。
插值法包括 线性插值 、 多项式插值 、 样条插 。
函数merge的参数how取值有 left(左连接) 、 right(右连接) 、 outer(外连接) 和 inner(内连接) 。
三、简答题
- 缺失值处理方法。
答:
(1)删除法
(2)固定值替换法
(3)填充法
(4)插值法
- 数据合并连接与重塑的函数。
答:
pd.merge(left, right, how=’inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(‘_x’,’_y’))
DataFrame内置的join方法是一种快速合并的方法。它默认以index作为对齐的列。左右两个DataFrame具有重复列时需要指定重复列的前缀,加以分区,使用lsuffix和rsuffix实现。
pd.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
combine_first合并
数据重塑是将DataFrame的行或列进行旋转的操作,函数stack将DataFrame的列旋转为行,unstack将DataFrame的行旋转为列。
- 数据变换种类有哪些。
答:
虚拟变量
函数变换
连续属性离散化
规范化
随机采样
第六章 机器学习
一、选择题
- 监督学习包括( B、C )
A. 降维 B. 回归 C. 分类 D. 聚类
- 鸢尾花数据集属于( A )
A. load数据集 B. make数据集 C. 可在线下载的数据集 D. svmlight/libsvm格式的数据集
- 数据集拆分为训练集和测试集的函数是( D )
A. cross_val_score B. PCA C. score D. train_test_split
- 支持向量机用来回归分析的算法是( B )
A. SVM B. SVC C. SVR D. SVN
二、填空题
机器学习可以分为监督学习和 无监督学习 。
数据预处理的模块是 preprocessing 。
函数sklearn .decomposition.PCA(n_components=’mle’,whiten=False,svd_solver=’auto’)中参数n_components取值’mle’用MLE算法根据特征的 方差分布情况 选择一定数量的主成分特征来降维。
三、简答题
- 朴素贝叶斯。
答:朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
- 模型评估。
答:
模型评估是对预测质量的评估,即模型的评价,主要有三种方法。
- 模型自带 score函数
使用model.score(X_test,y_test)可以获得模型的评价,其值为[0,1]之间的数,1表示最好。
参数X_test表示测试集,参数y_test表示测试集对应的值。
- cross_val_score
函数cross_val_score会得到一个对于当前模型的评估得分。在该函数中最主要的参数有两个:scoring和cv。
scoring参数设定打分的方式,比如accuracy、average_precision等。
cv参数表示数据划分方式,通常默认的是KFold或者stratifiedKFold方法。
from sklearn.cross_validation import cross_val_score
scores = cross_val_score(knn, X, y, scoring=’accuracy’)
- 评估函数
Sklearn预定义了一些评估函数,这些评估函数也可以用来设置corss_val_score的scoring的值,也可以调函函数名称获取评估值。
- 聚类分析。
答:
聚类分析指将物理对象或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。聚类分析的目标就是在相似的基础上收集数据来分类。聚类源于很多领域,包括数学、计算机科学、统计学、生物学和经济学等。
聚类与分类的不同在于聚类所要求划分的类是未知的。
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等;目前流行的是K-均值、K-中心点等人工智能的聚类分析算法。
聚类分析是一种探索性的分析,能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。
Sklearn实现了多种聚类算法,如表6-6所示。
表6-6 常用聚类算法
| 序号 | 函数名称 | 参数 | 距离度量 |
|---|---|---|---|
| 1 | K-Means | 簇数 | 点之间距离 |
| 2 | Spectral clustering | 簇数 | 图距离 |
| 3 | Ward hierarchical clustering | 簇数 | 点之间距离 |
| 4 | Agglomerative clustering | 簇数、连接类型、距离 | 任意成对点线图间的距离 |
| 5 | DBSCA | 半径大小、最低成员数目 | 最近的点之间的距离 |
| 6 | Birch | 分支因子、阈值、可选全局集群 | 点之间的欧式距离 |
致谢:感谢老王提供的资源 ©老王
