Python与数据分析期末复习
21年考情
题型:
填空题10分
代码填空20分
读程序写结果40分
程序设计10分(一道)
大数据案例论述题20分(一道)
P1、P2 1.1.1数据分析的概念:分哪几个部分?1.1.2数据分析的流程:各有什么用?
P4、P5 1.2.2 熟悉Numpy、Pandas、Matplotlib的用处。
P15 2.1 Numpy多维数组下的一段话,即Numpy多维数组的作用?
P18 arange函数、linspace函数、logspace函的使用。
P19 最下面 5.随机数数组,熟悉前四个函数的使用(rand、randint、randn、seed)
P39 示例2-34,四个函数都要会用
P46 2.5.2矩阵行列式、示例2-44
P47 2.5.4线性方程组、示例2-46
P49 四、读程序的1、2题
P54 引言matplotlib的作用、3.1.1绘制线形图、示例3-1,熟悉plot函数的使用。
P74 示例3-25用figure函数创建子图
P89 pandas有哪几种数据结构、概念
P91 数据帧DataFrame的定义和使用
P106 示例4-13更换索引
P112 示例4-21排序
P134 数据清洗的定义
P135 缺失值(检测缺失值的方法,处理缺失值有哪几种方法)
P138 示例5-5填充缺失值fillna函数的应用
Ps:前途是光明的,道路是曲折的!
逐点击破
零、数据分析的概念?分哪几个部分?
数据分析概念:数据分析是指选用适当的分析方法对收集来的大量数据进行分析、提取有用的信息和形成结论、对数据加以详细研究和概括总结的过程。
广义的数据分析包括:
- 狭义数据分析
- 数据挖掘
共两部分。
狭义数据分析
是指根据分析目的,采用对比分析、分组分析、交叉分析和回归分析等方法,对收集的数据进行处理与分析,提取有价值的信息,发挥数据的作用,得到一个特征统计量结果的过程。
数据挖掘
是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过应用聚类模型、分类模型、回归和关联规则等技术,挖掘潜在价值的过程。
一、数据分析的流程?各有什么用?
数据分析已经逐渐演化为一种解决问题的过程,典型的数据分析流程如下:
- 需求分析
- 数据获取
- 数据预处理
- 分析与建模
- 模型评价与优化
- 部署
需求分析:需求分析的主要内容是根据数据分析需求方的要求和实际情况,结合现有的数据情况,提出数据分析需求的整体分析方向、分析内容,最终和需求方达成一致意见。
数据获取:数据获取是根据需求分析的结果提取、收集数据。
数据预处理:数据预处理是指对数据进行数据合并、数据清洗和数据变换,并直接用于分析建模的这一过程的总称。
分析与建模:分析与建模是指通过对比分析、分组分析、交叉分析、回归分析deng分析方法,以及聚类模型、分类模型、关联模型等模型与算法,发现数据中有价值的信息,并得出结论的过程。
模型评价与优化:模型评价是指对于已经建立的模型,根据其模型的类别,使用不同指标评价其性能优劣的过程。
二、 熟悉Numpy、Pandas、Matplotlib的用处。
Numpy:
Numpy是Numerical Python的简称,是Python语言的一个科学计算的扩展程序库,支持大量的多维数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。Numpy主要提供以下内容:
- 快速高效的多维数组对象ndarray
- 广播功能函数,广播是一种对数组执行数学运算的函数,其执行的是元素级计算。广播提供了算术运算期间处理不同形状的数组的能力。
- 读/写硬盘上基于数组的数据集工具
- 线性代数运算、傅里叶变换及随机数生成功能
- 将C/C++、Fortran代码集成到Python的工具
除了为Python提供快速的数组处理能力外,Numpy在数据分析方面还有另一个主要作用,即作为算法之间传递数据的容器。对于数值型数据,使用Numpy数组存储和处理数据要比使用内置的Python数据结构高效得多。此外,由其他语言(如C语言)编写的库可以直接操作Numpy数组中的数据,无需进行任何数据复制工作。
Pandas:
- Pandas是Python的数据分析核心库,最初被作为金融数据分析工具而开发出来。Pandas为时间序列分析提供了很好的支持。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,提供一些列能够快速、便捷地处理结构化数据的结构和函数。Python之所以成为强大而高效的数据分析环境与他息息相关。Pandas兼具Numpy高性能的数组计算功能以及电子表格和关系型数据库的灵活数据处理功能,它提供了复杂精细的索引功能,以便便捷地完成重塑、切片和切换、聚合及选取数据子集等操作。
Matplotlib:
- Matplotlib是最流行的用于绘制数据图形地Python库,它以各种硬件拷贝格式和跨平台地交互式环境生成出高质量的图形。
三 、 Numpy多维数组下的一段话,即Numpy多维数组的作用?
Numpy提供了一个名为ndarray的多维数组对象,该数组元素具有固定的大小,即Numpy数组元素是同质的,只能存放同一种数据类型的对象,因此能够确定存储数组所需空间的大小,能够运用向量化运算来处理整个数组,具有较高的运算效率。
四、 arange函数、linspace函数、logspace函的使用。
从数值范围创建数组的Numpy函数有三个:arange()\linspace()和logspace()。
arange()函数
函数arange()根据start指定的范围以及step设置的步长,生成一个ndarry对象,函数格式如下:
1 | |
其中的参数如表所示:
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为0 |
| stop | 终止值(不包含) |
| step | 步长,默认为1 |
| dtype | 返回的ndarray的数据类型,如果没有提供,则会使用输入数据的类型 |
linspace()函数
Linspace()函数用于创建一个一维数组,数组是一个等差数列构成的,其格式如下:
1 | |
其中参数如表所示
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为0 |
| stop | 序列的终止值,如果endpoint为True,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| dtype | ndarray的数据类型 |
| endpoint | 该值为True时,数列中包含stop值,反之不包含,默认为True |
| retstep | 如果为True,生成的数组中会显示间距,反之不显示 |
logspace()函数
logspace()函数用于创建一个对数运算的等比数列,其格式如下:
1 | |
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为0 |
| stop | 序列的终止值,如果endpoint为True,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| dtype | ndarray的数据类型 |
| endpoint | 该值为True时,数列中包含stop值,反之不包含,默认为True |
| base | 对数log的底数 |
实例:从数值范围创建数组
1 | |

五、 最下面 5.随机数数组,熟悉前四个函数的使用(rand、randint、randn、seed)
rand()函数
rand()函数产生一个指定形状的数组,数组中的值服从[0,1)之间的均匀分布,其格式如下:
1 | |
其中,参数d0,d1,…,dn为int型,可选。如果没有参数则返回一个float型的随机数。该随机数服从[0,1]之间的均匀分布。其返回值是一个ndarray对象或者一个float型的值。
示例:rand()函数的应用
1 | |

randn()函数
函数randn()返回一个指定形状的数组,数组中的值服从标准正态分布(均值为0,方差为1),其格式如下:
1 | |
其中,参数d0,d1,…,dn为int型,可选。如果没有参数,则返回一个服从标准正态分布的float型随机数。
返回值:ndarray对象或者float
示例:randn()函数的应用
1 | |

randint()函数
randint()函数生成一个在区间[low,high)中离散均匀抽样的数组,其格式如下:
1 | |
函数参数说明如下:
①low、high:int型,指定抽样区间[low,high)
②size:int型或int型元组,指定形状
③dtype:可选参数,指定数据类型,如int、int64等,默认为np.int
返回值:如果指定了size,则返回一个int型的ndarray对象,否则返回一个服从该分布的int型随机数。
示例:randint()函数的应用
1 | |

六、 示例2-34,四个函数都要会用
add()、subtract()、multiply()和divide()函数的应用。
1 | |
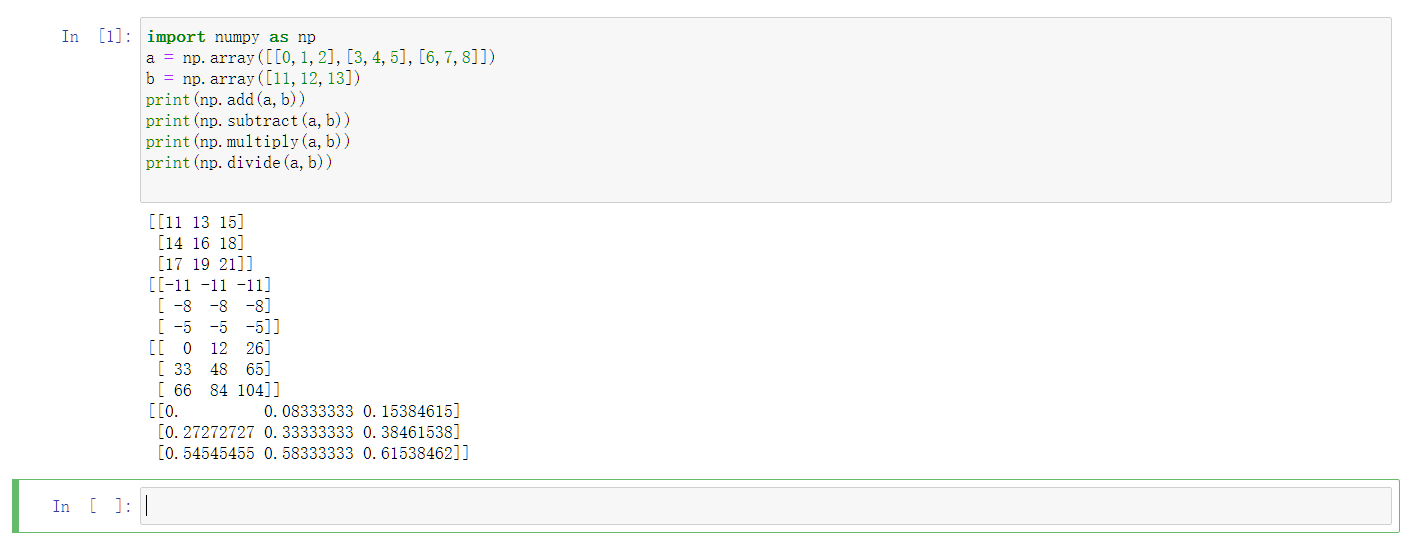
解释一下:函数用法对应英文单词的意思。首尾要相同!(1,3)(3,1)就可以,(1,3)(2,3)就不行。
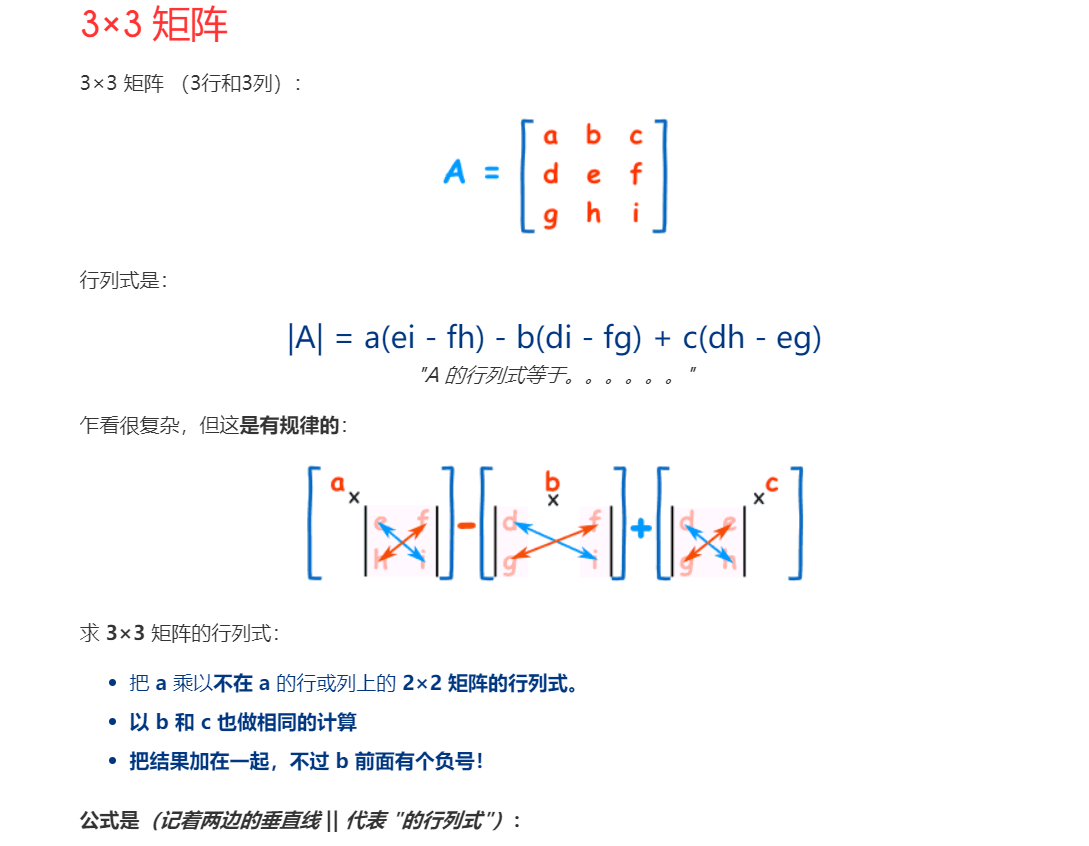
七、矩阵行列式、示例2-44
numpy.linalg.det()函数计算输入矩阵的行列式。
1 | |

解释:对角线相乘然后一减,后面有4是因为机器码转换成数据时精度问题。


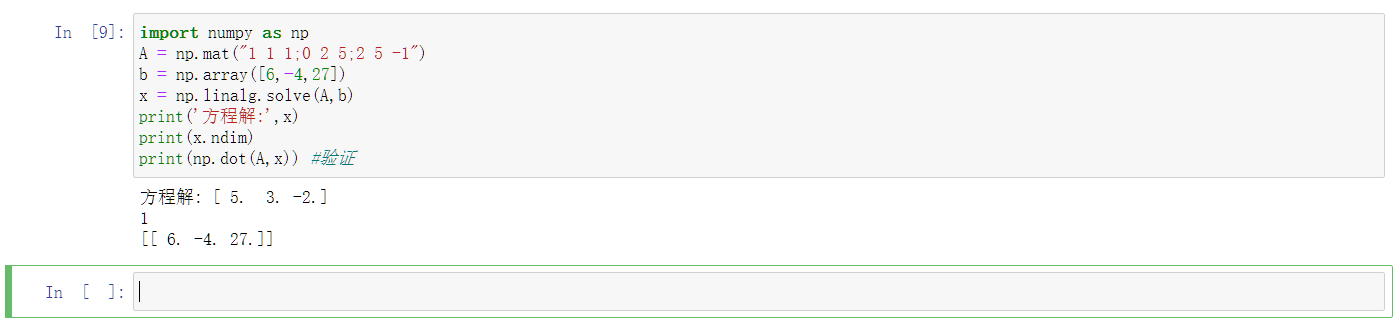
八、线性方程组、示例2-46
numpy.linalg中的solve()函数可以求解线性方程组。
线性方程Ax=b,其中A是一个矩阵,b是一维或者二维数组,而x是未知量。
1 | |
代码求解:
1 | |
上面代码的创建矩阵也可写成如下形式:
1 | |
九、读程序的1、2题
以下程序的执行结果是:
1
2
3
4
5import numpy as np
a = np.arange(12).reshape(2,6)
c = a.ravel()
c[0] = 100
print(a)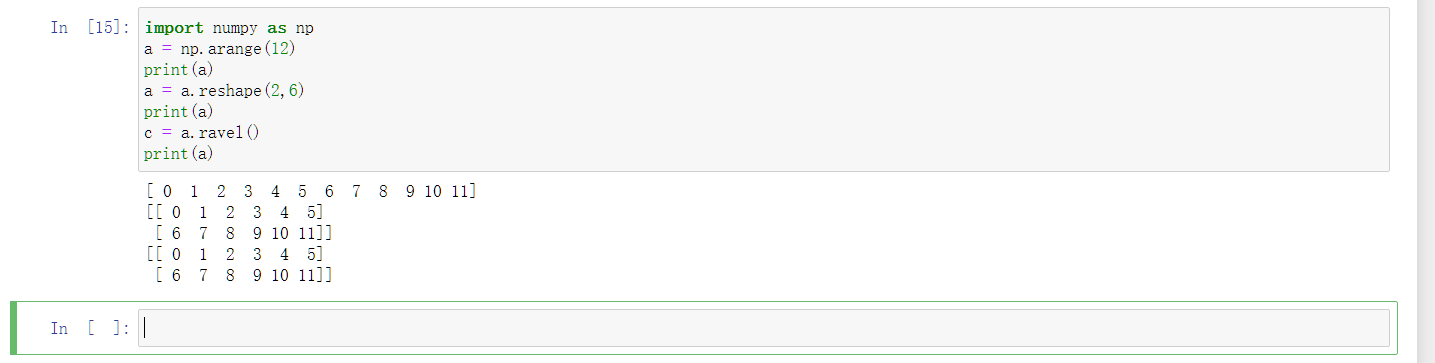
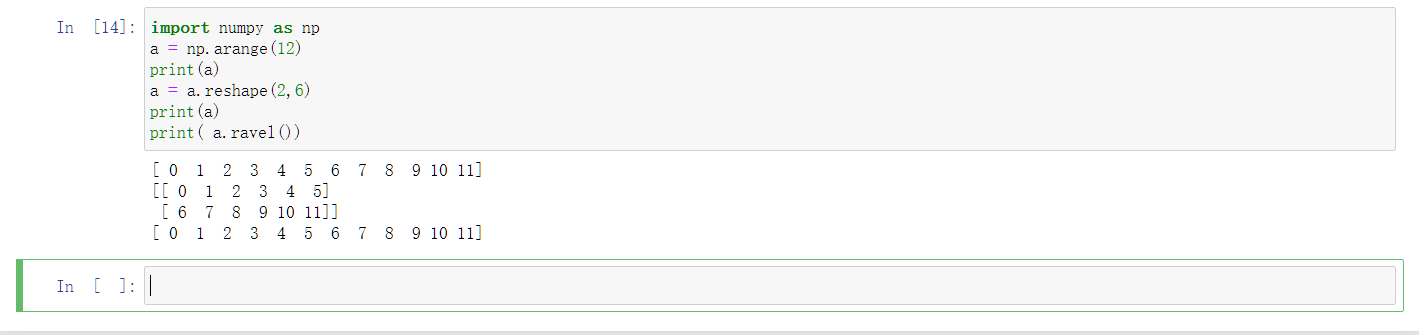
说明ravel不会动原数组对象。
以下程序执行结果是:
1
2
3
4import numpy as np
a = np.arange(9)
b = np.split(a,3)
print(b)
十、引言matplotlib的作用、绘制线形图、示例3-1,熟悉plot函数的使用。
matplotlib的作用:
数据可视化是形象展示数据的主要手段,也是数据分析的重要组成部分。matplotlib是一个基于Python的图形可视化工具,支持多种图形的绘制,并支持完整的图标样式和个行化设置,功能强大且易学易用。
绘制线形图:
线形图是最基本的图表类型,常用于绘制连续的数据。通过绘制线形图,可以表现出数据的一种趋势变化。Matplotlib的plot()函数用来绘制线形图,其格式如下:
1 | |
args是一个可变长的参数,允许使用可选格式字符串的多个x、y对,并且x可以省略。当省略x时,通过y索引0,1…,n-1作为x。
kwargs参数也是一个可变长的参数,允许对线形图的显示效果进行设置。
1 | |
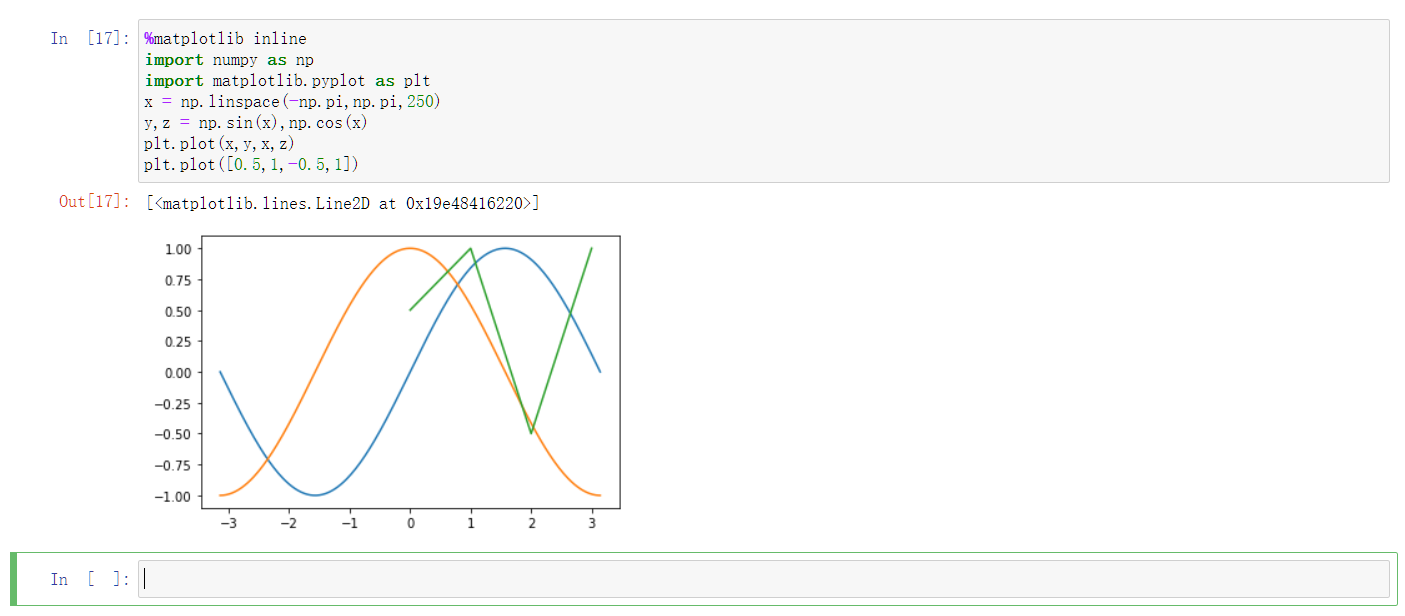
程序分析:
- %matplotlib inline的作用是在Jupyter Notebook中显示图形,使用其他开发工具,这行代码可以不要
- import matplotlib.pyplot as plt的作用是导入matplotlib的pyplot模块
- x = np.linspace(-np.pi,np.pi,250)的作用是生成一个由250个浮点数组成的数组
- y,z = np.sin(x),np.cos(x)的作用是计算出数组的正弦、余弦值,并赋值给y和z两个变量
- plt.plot(x,y,x,z)绘制两条线形图,分别是正弦和余弦曲线
- plt.plot([0.5,1,-0.5,1])绘制线形图,其中y轴的值是[0.5,1,-0.5,1],而x轴的值是[0,1,2,3],即数组[0.5,1,-0.5,1]的索引
十一、 示例3-25用figure函数创建子图
subplot(nrows,ncols,plot_number)函数创建子图,其中参数nrows、ncols表示行数和列数,决定了子图的个数;plot_number表示当前是第几个子图。
利用figure()函数创建子图:
1 | |
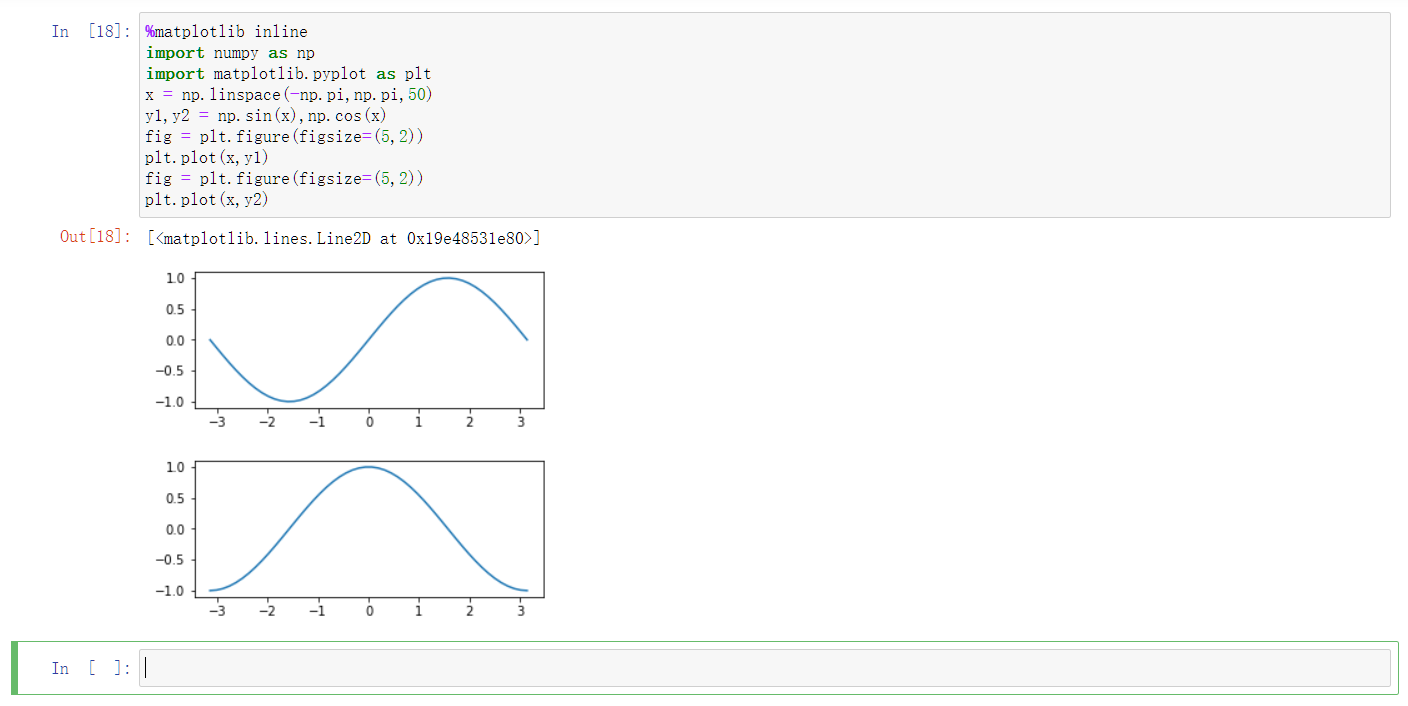
十二、 pandas有哪几种数据结构、概念
Pandas有3钟数据结构:系列(Series)、数据帧(DataFrame)和面板(Panel),这些数据结构可以构建在Numpy数组上。
Series系列
系列是具有均匀数据的一维数据结构,其特点是:均匀数据、尺寸大小不变、数据的值可变。
系列是能够保存任何数据类型的数据(整数、字符串、浮点数、Python对象等)的一维标记数组。
Pandas系列可以使用以下构造函数构建:
1 | |
数据帧
数据帧(DataFrame)是一个具有异构数据的二维数组,其特点是异构数据、大小可变、数据可变。数据帧是Pandas使用最多的数据结构。
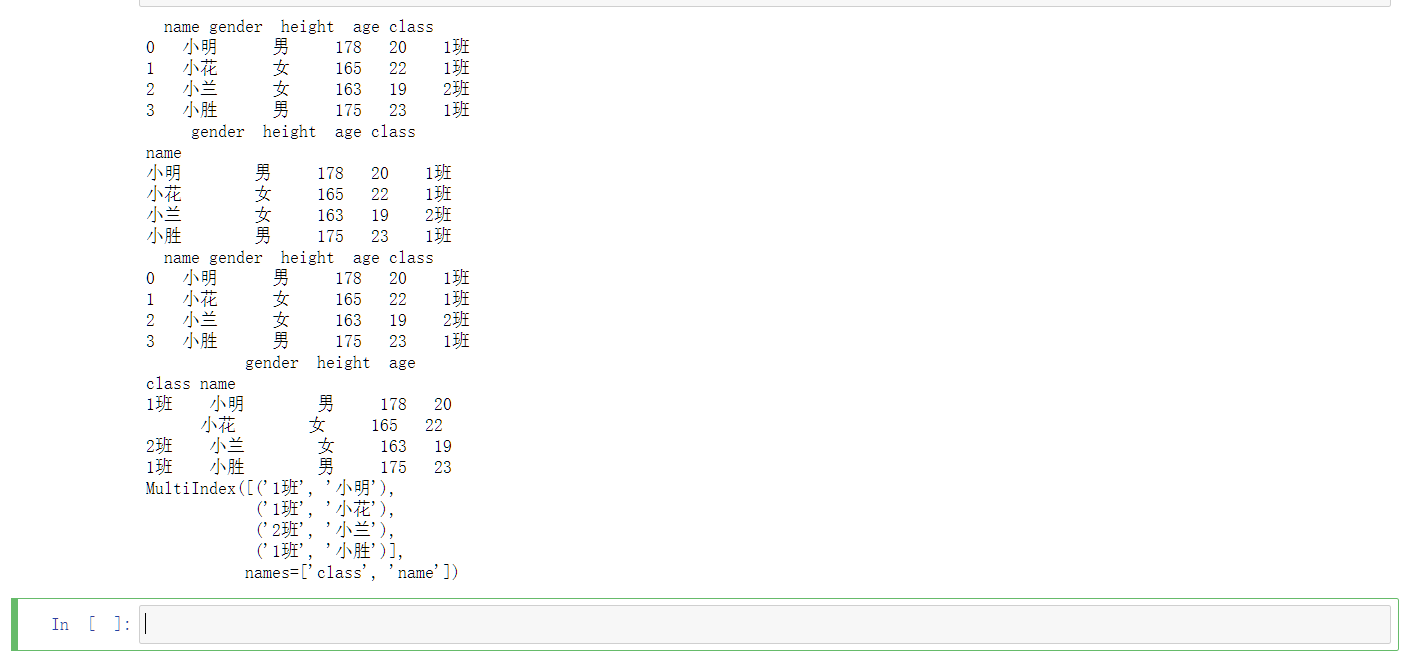
数据以行和列表示,每行是一条记录(对象),每列表示一个属性,属性数据具有数据类型。例如,姓名是字符串,年龄是整数,如表所示。
| 姓名 | 性别 | 年龄 | 身高 | 班级 |
|---|---|---|---|---|
| 小明 | 男 | 20 | 178 | 1班 |
| 小花 | 女 | 22 | 165 | 1班 |
| 小兰 | 女 | 19 | 163 | 2班 |
| 小胜 | 男 | 23 | 175 | 1班 |
Pandas中的DataFrame可以使用以下构造函数创建:
1 | |
面板
面板是具有异构数据的三维数据结构。其特点是:异构数据、大小可变、数据可变。
可以使用以下构造函数创建面板:
1 | |
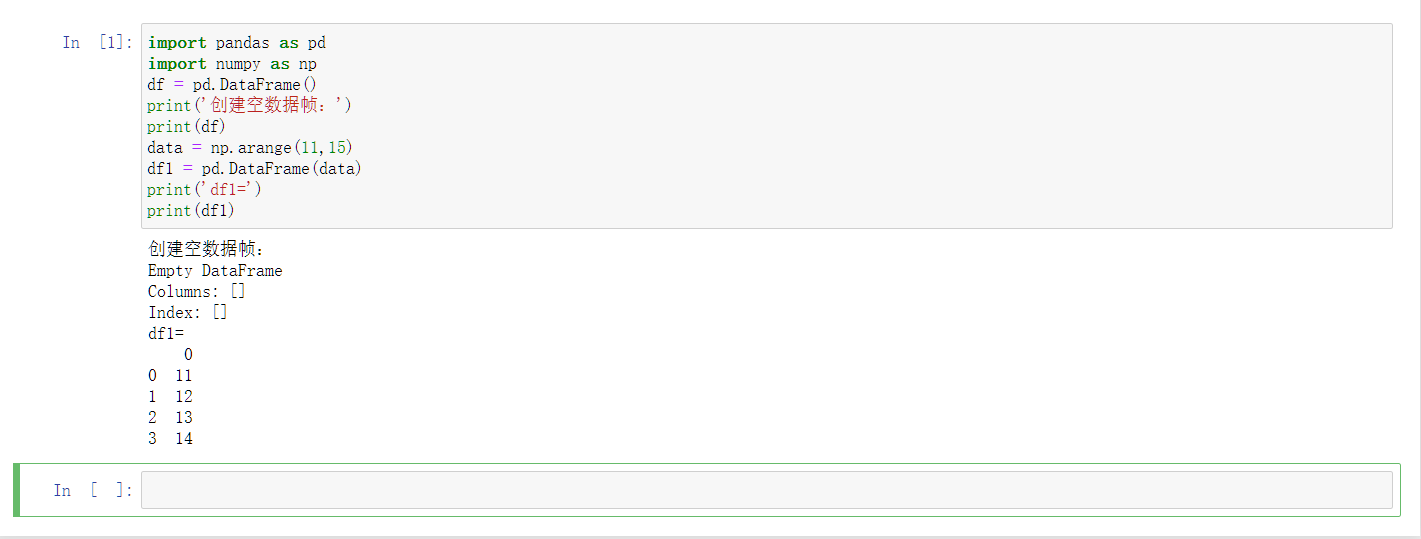
十三、 数据帧DataFrame的定义和使用
Pandas数据帧可以使用各种输入创建,如列表、字典、系列、NumPy的ndarrays、Series或另一个数据帧等。
1 | |
1 | |
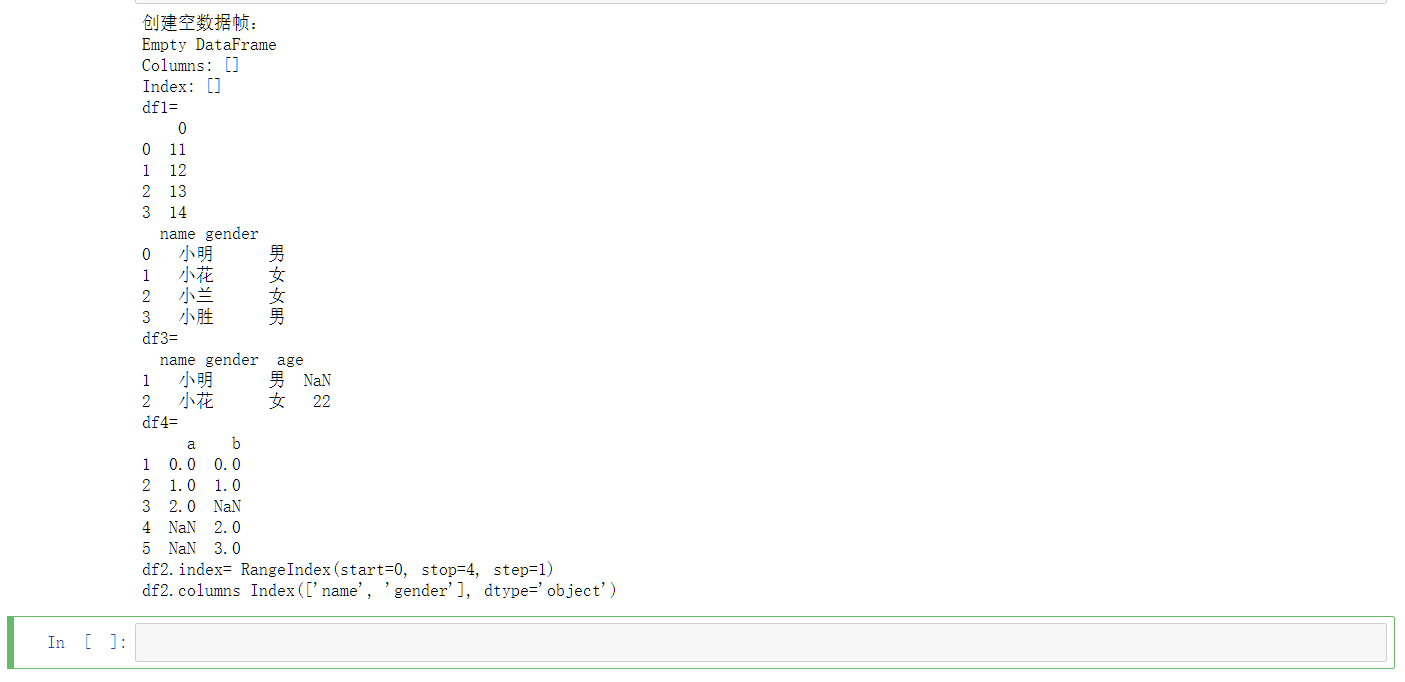
十四、示例4-13更换索引
reset_index()函数:
reset_index()函数可以还原索引,重新变为默认的整型索引,其格式如下:
1 | |
参数说明如下:
- level:控制了具体要还原的那个等级的索引
- drop:为False,则索引列会被还原为普通列,否则会丢失
1 | |
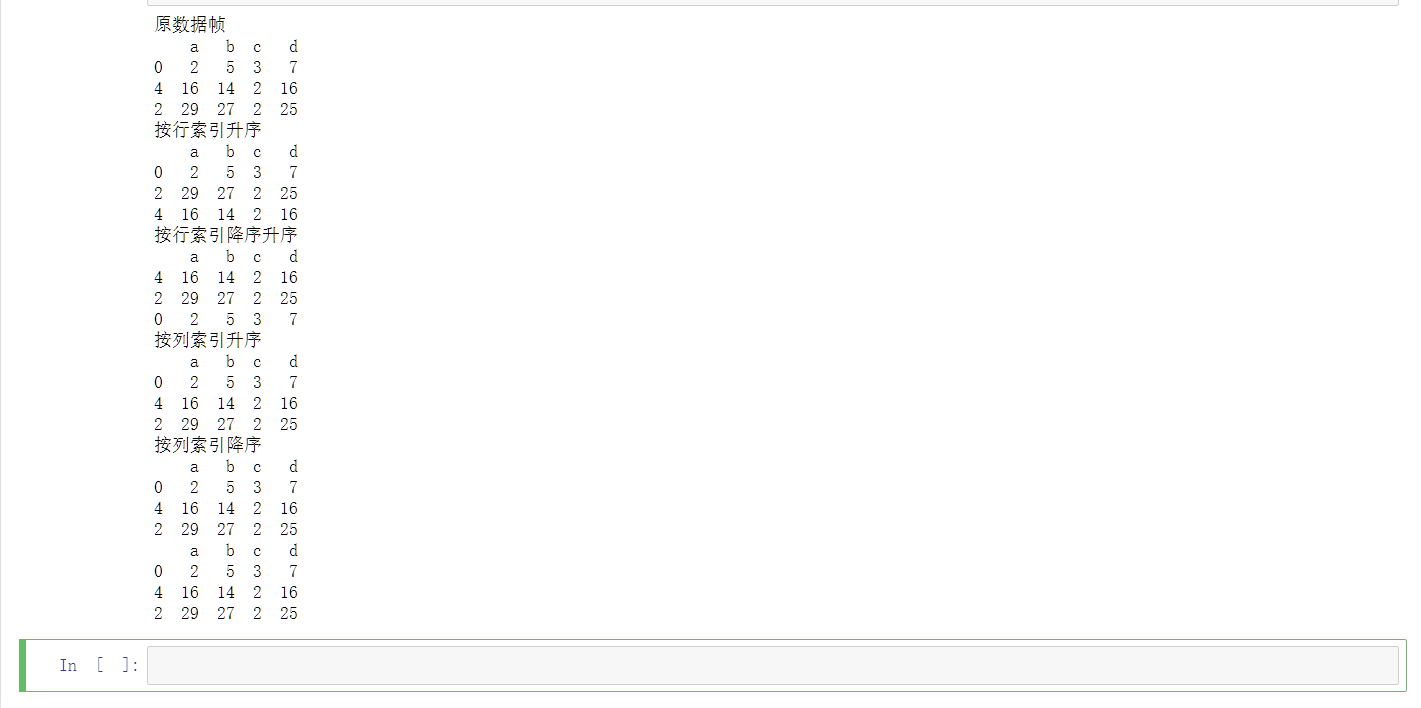
十五、示例4-21排序
Pandas有两种排序方式,分别是:按标签排序和按实际值排序。
sort_index()函数
1 | |
参数说明如下:
- axis:0按照行名排序;1按照列名排序。
- level:默认None,否则按照给定的level顺序排列。
- ascending:默认True升序排列;False降序排列。
- inplace:默认False,否则排序之后的数据直接替换原来的数据集。
- kind:默认quicksort,排序的方法(快速排序)。
- na_position:缺失值默认排在最后{‘first’,’last’}。
- by:按照那一列的数据进行排序。
sort_values()函数
1 | |
参数说明如下:
- axis:坐标轴,取值为0和1,默认为0.默认按照索引排序,即纵向排序,如果为1,则是横向排序。
- by:是一个字符串或字符串列表,如果axis=0,则by=”列名”;如果axis=1,则by=”行名”。
- ascending:布尔型,True则升序,可以是[True,False],即第一字段升序,第二个降序。
- inplace:布尔型,是否用排序后的数据框替换现有的数据框。
- kind:排序方法。
- na_position:{‘first’,’last’},默认值为’last’,默认缺失值排在最后面。
1 | |
十六、数据清洗的定义
数据清理主要是处理原始数据中的重复数据、缺失数据和异常数据,使数据分析不受无效数据影响。
十七、 缺失值(检测缺失值的方法?处理缺失值有哪几种方法?)
数据采集中由于设备或人为原因可能造成的部分数据缺失,数据缺失会对数据分析造成不利影响,因此必须加以处理。
检测缺失值
在处理缺失值前,需要先找到缺失值,使用人工查找缺失值,效率低而且容易遗漏。isnull()函数可以检查数据中缺失值,返回一个布尔矩阵,每一个布尔值表示对应位置的数据是否缺失。
notnull()函数与isnull()函数意思相反。返回的布尔值为True时表示非缺失值。
1 | |
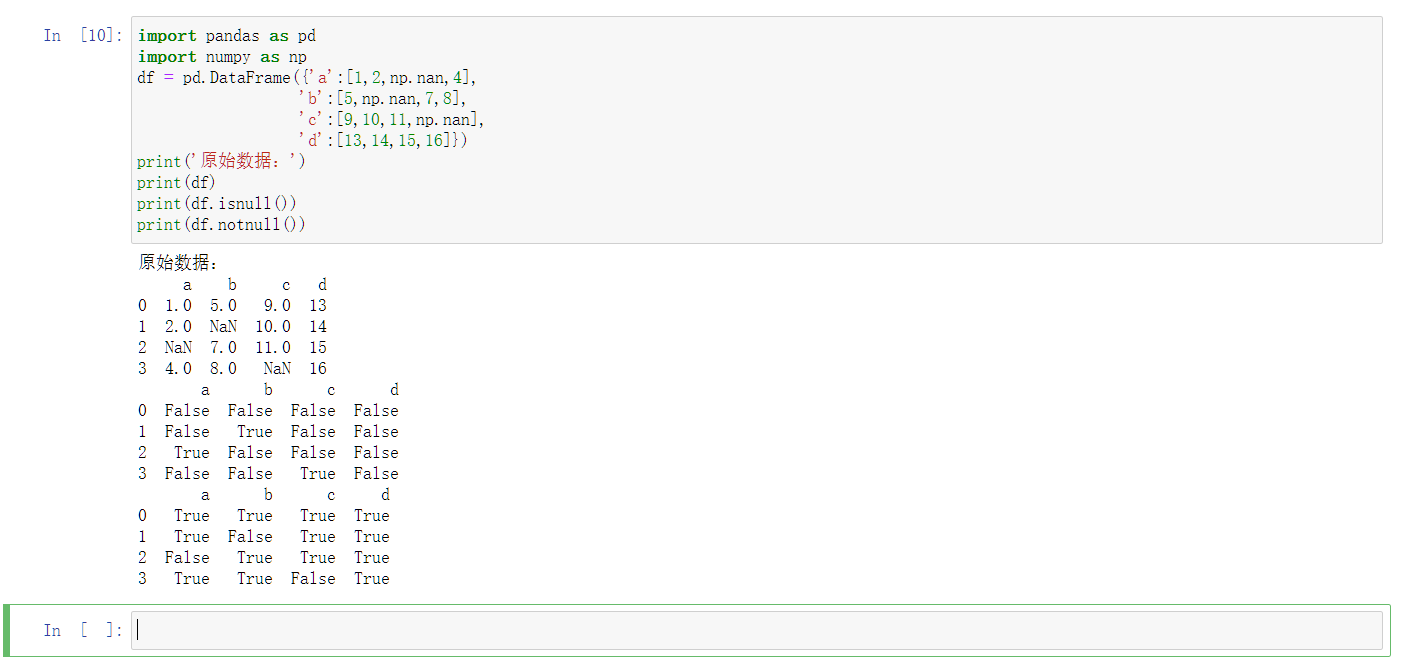
程序分析:
- df.isnull()函数返回df数据帧中的数据是否为NaN值的boolean型数据矩阵,如果数据为NaN值,矩阵对应位置为True,否则为False
- df.notnull()函数与df.isnull()函数返回的boolean值正好相反
处理缺失值
缺失值处理主要有4种处理方法:
- 删除法
- 固定值替换法
- 填充法
- 插值法
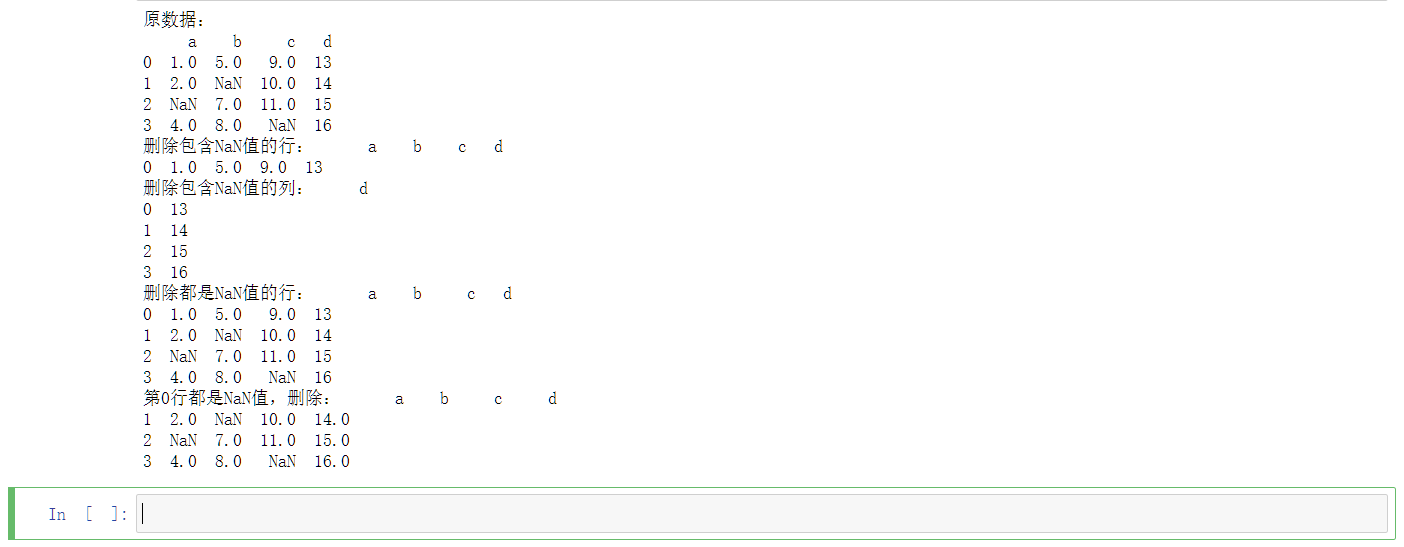
删除法
当有缺失值时,删除是最简单的处理方法,使用删除法要考虑两种情况:只要有NaN值就删除;都是NaN值才删除。删除NaN值数据通过函数dropna()实现。
- 参数how有两个取值:any表示如果存在任何NaN值,则删除该行数据,all表示如果所有的值均为NaN值,才删除该行。
- 参数thresh是一个int值,默认值为None,表示要求每排至少N个非NAN值。
- 参数subset是一个类似数组,表示全都是NaN值的集合。
- 参数inplace是一个boolean,默认值False,如果为True,则返回None,但是原数据被修改。
1 | |
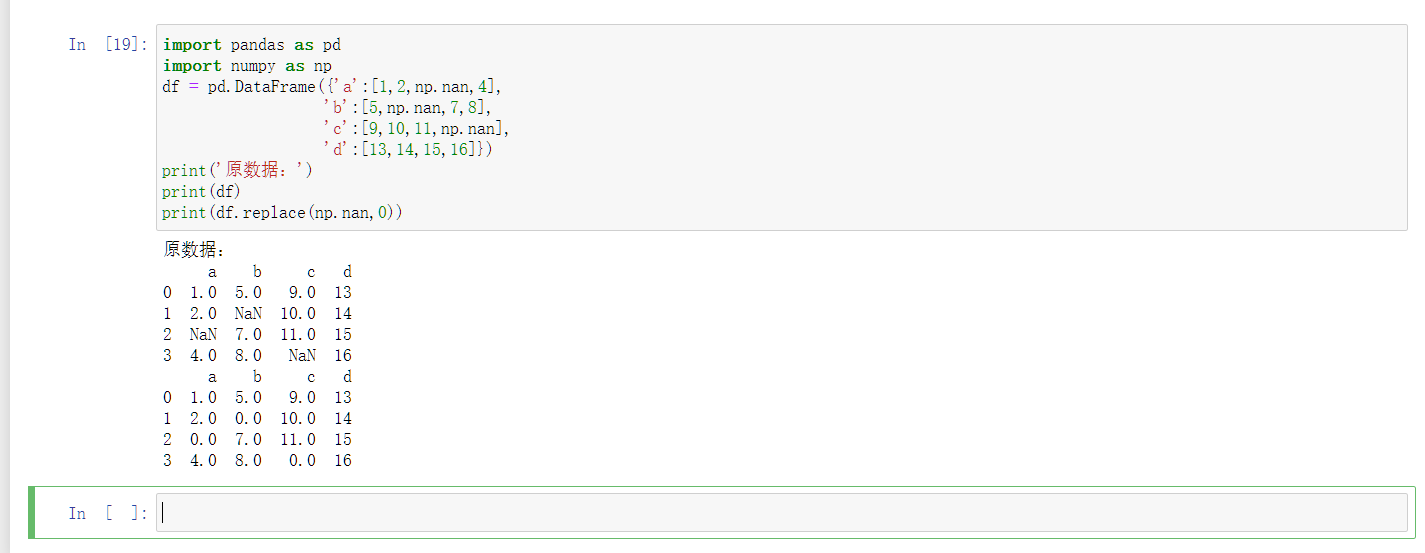
固定值替换法
使用固定值替换NaN值,是一种简单的处理方法,但是效果不好。
1 | |
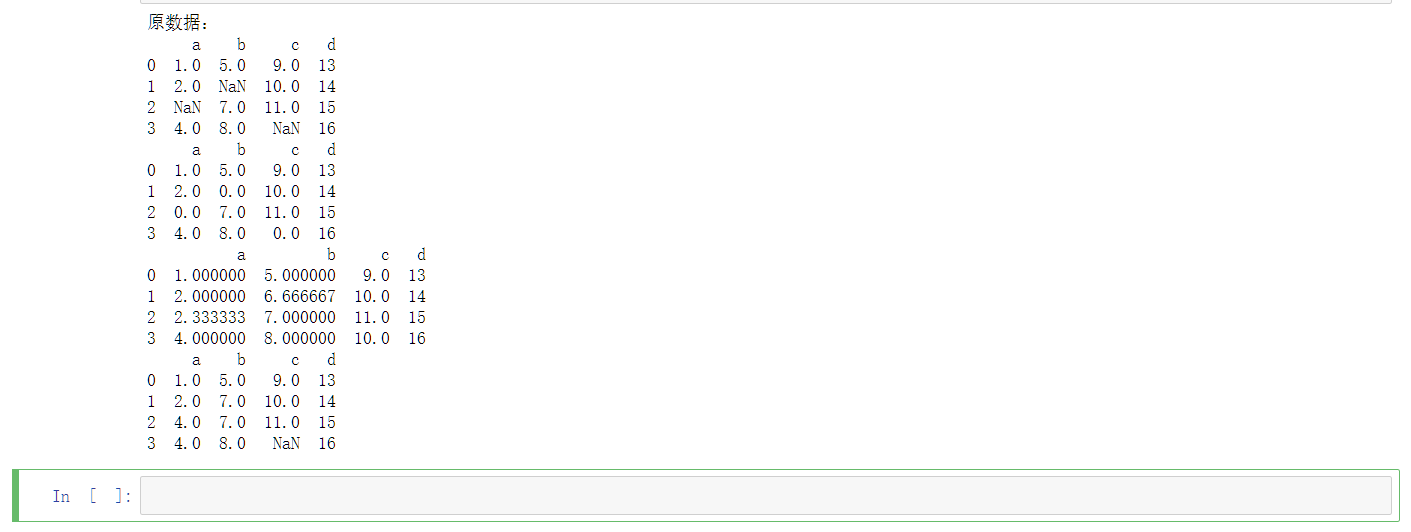
填充法
使用fillna()函数来填充NaN值,是一种常用的处理方法。
参数nethod取值:backfill、bfill、pad、ffill、None,默认值:None。pad、ffill表示向前填充,backfill、bfill表示向后填充。
1 | |
插值法(牛逼的方法)
上述处理缺失值的方法存在明显的缺陷,尤其是在数据量不够丰富时,删除法基本上是不具有可行性的,。除了上述方法外,还有一种效果更好的方法——插值法。
插值法有3种常用的方法:线性插值,多项式插值和样条插值。
- 线性插值是根据已知数值构建线性方程组,通过求解线性方程组获取缺失值;
- 多项式插值是通过拟合多项式,通过多项式求解缺失值,多项式插值中最常用的是拉格朗日插值法和牛顿插值法;
- 样条插值是通过可变样条做出一条经过一系列点的光滑曲线的插值方法;
线性插值和多项式插值:
1 | |
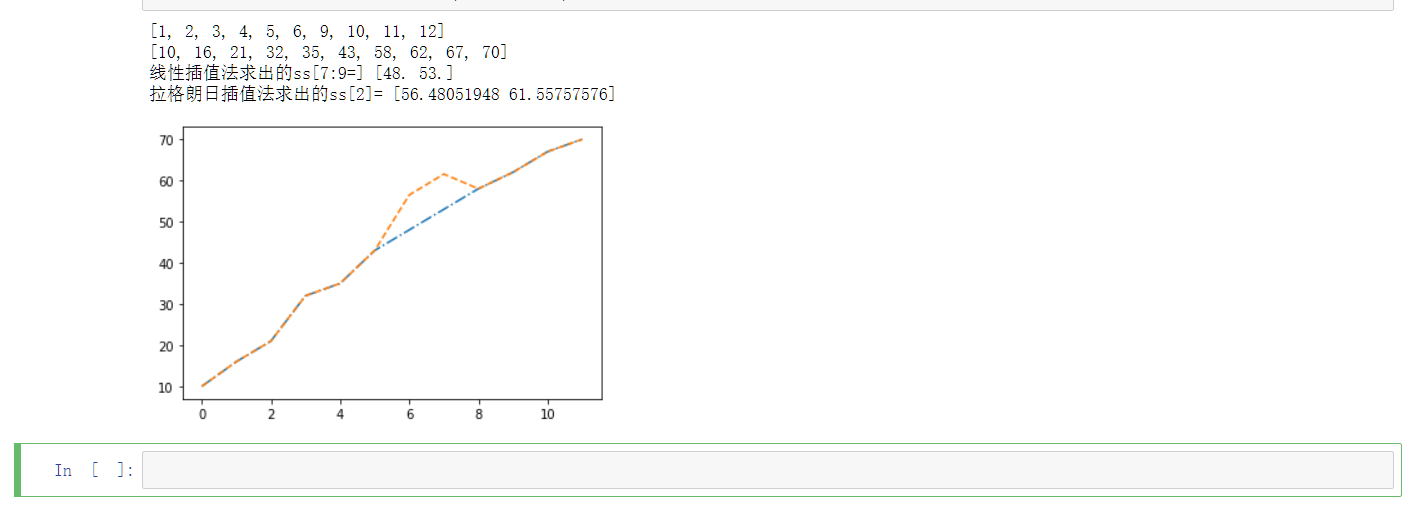
样条插值:
1 | |