大数据案例分析复习-大学的最后一门考试
写在前面
这是大学的最后一门考试课,在今天复习的时候,发生了很多事情,这将会永远被历史铭记。
@Author:CQYN
大数据案例分析
名词解释
维度建模
维度建模是数据仓库建设中的一种数据建模方法,是一种将数据结构化的逻辑设计方法,它将客观世界划分为度量和上下文。
数据仓库
数据仓库,英文名称为Data Warehouse。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
数据集市
数据集市,也叫数据市场。数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
ETL
ETL,是英文Extract-Transform-Load的缩写,用于描述将数据从来源端经过抽取、转换、加载至目的端的过程。ETL一词常用在数据仓库,但其对象并不限于数据仓库。
大数据可视化
大数据可视化是在大数据时代对海量数据的可视化表示的一种科学技术研究。
数据类型
结构化数据
- 结构化数据(有时候被称为关系数据),遵循某种严格架构的数据,因此所有数据都具有相同的字段或属性。
半结构化数据
- 非关系模型的,有基本固定结构模式的数据
非结构化数据
- 数据结构不规则或者不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据
东航案例分析
业务痛点
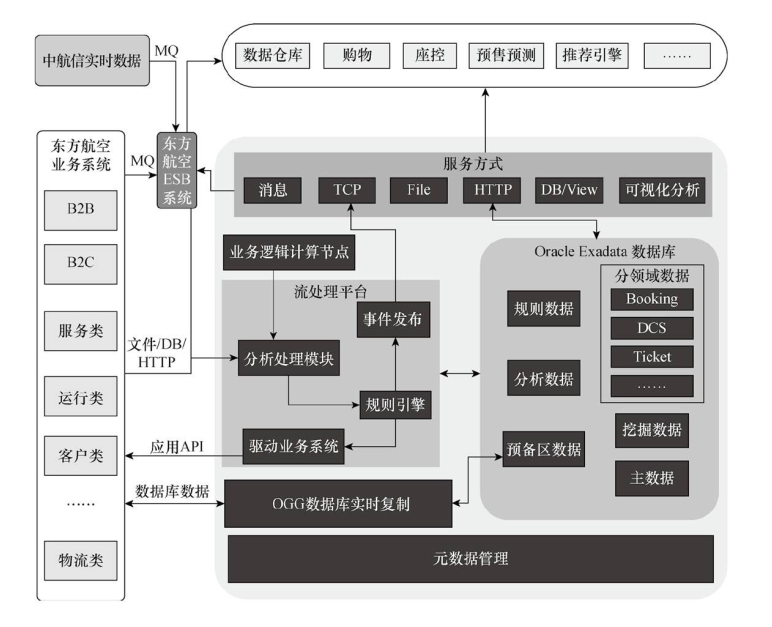
在常规情况下,东方航空是从中航信获得旅客的购票订座、值机离港等实时数据,每天的数据量极大,而这些数据是报文形式的,是非结构化数据,需要进行解析。按传统的方式处理,这样的数据必须入库再进行分析,通常需要数个小时,如此一来东航就无法及时、准确地获知已出售座位数以及离港的实时数据,导致场景应用不及时。
- 难以及时调整销售策略
- 难以进行精准营销
- 难以进行实时航班监控
- 非实时全渠道数据,无法提供统一服务
- 非及时的航班变更通知
系统痛点
系统痛点主要是从系统层面来看,关系复杂、难扩展、难以满足业务发展需求,表现在订座、离港和电商三大平台之间相互割裂、无法融合。
如何将中航信提供的实时数据应用于实时的决策和服务,是东航曾面临的重大难题
大数据项目业务目标
- 学习国内外先进的大数据项目成功经验,聚焦客户和产品中心,以“东方万里行会员”常旅客信息为基础,结合内部其他应用系统和新兴大数据,围绕客户和产品信息建立大数据分析体系,充分挖掘信息的价值,并应用于东方航空的应用和服务场景,切实辅助其他应用以提升业务处理能力,从而为会员用户提供更好的服务体验并实现会员收入提升。
大数据项目技术目标
与其他系统紧密配合,实现数据融合,方便整个企业的数据统一管理与分析
提供数据应用,为企业全数据环境提供统一的展现和服务能力
为实时处理大数据平台提供数据分析模型和实时联合数据访问支撑,为数据仓库提供数据卸载和高耗时数据处理能力卸载,降低在数据仓库等高价值体系上的成本。
进行大数据平台基础设施建设,为数据建模开发、界面展现及数据留存方面提供数据支持。
大数据任务框架图
- 系统解决方案架构图
海尔案例分析
商业模式
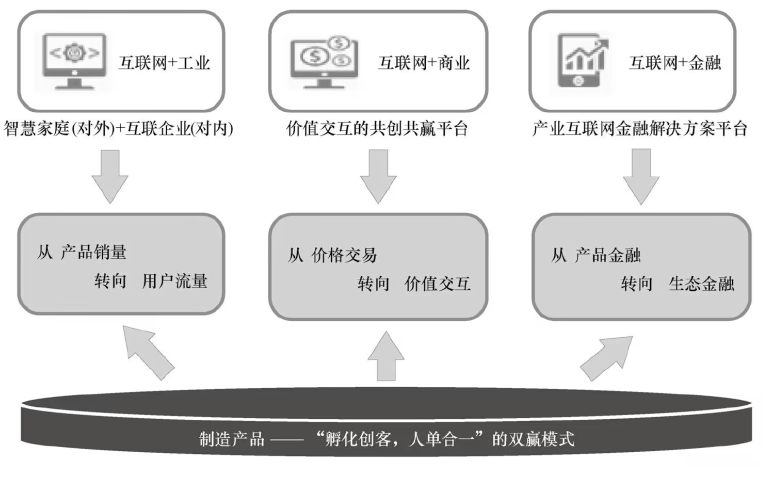
海尔集团新的商业模式基本思路是:从过去“制造产品”向“孵化创客,人单合一”的双赢模式转型。为了实现这一转变,海尔集团确立了“从产品销量转向用户流量”“从价格交易转向价值交互”和“从产品金融转向生态金融”三个新思想,重点推动“互联网+工业”“互联网+商业”和“互联网+金融”三大板块业务健康、快速地发展。
简而言之:
- 从”产品销量“转向”用户流量“
- “互联网+工业”
- 从”价格交易“转向”价值交互“
- ”互联网+商业“
- 从”产品金融“转向”生态金融“
- ”互联网+金融“
业务创新与目标
加强IT在体验服务、市场营销、经营运维和办公室管理中的全面应用。
实现:
- 聚焦以用户体验为核心的社群经济
- 建立全球化技术平台
- 优化数字化应用服务
- 助力后电商时代网络化转型
大数据驱动转型
- 集团层全面数据接入
- 优化模型及算法,发掘潜在的数据价值
- 切实提升数据实时分析能力,缩短显差及分析周期,全面提高业务洞察力
根据以上大数据战略,提出大数据驱动数字化转型:
- 以统一大数据云平台服务为依托,以DTS实时大数据引擎驱动体验,以实时大数据驱动显差关差,实现”驱动社群体验升级,驱动小微关差升级,自驱动业务升级“等方面的目标。
实验 (50分)
实验背景与目的
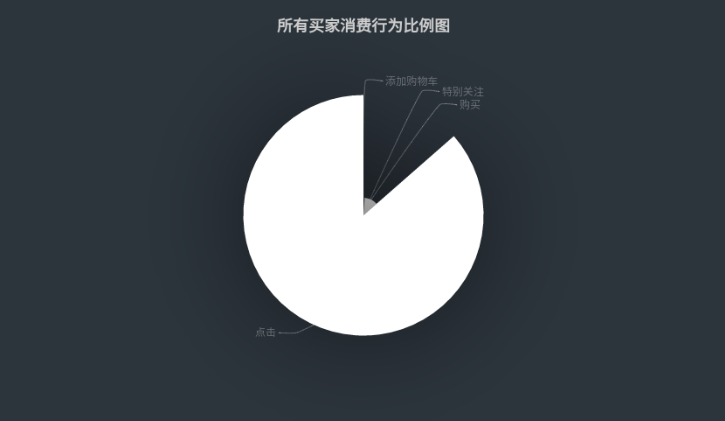
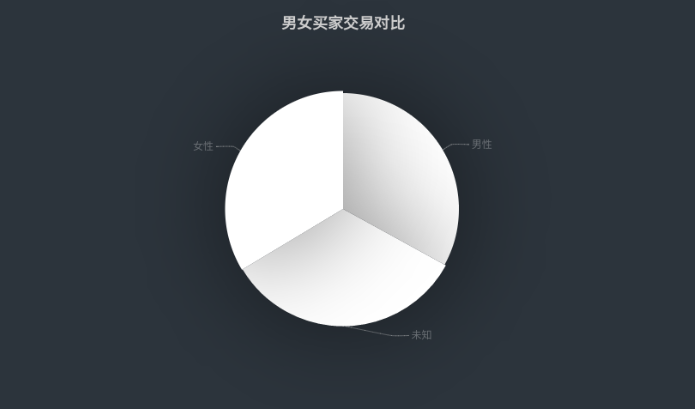
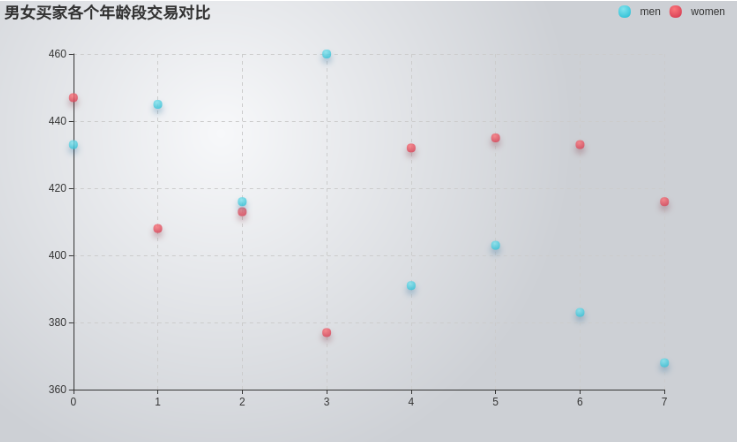
当下电商平台的日交易量日趋庞大,为了探索人们在双十一购物的消费行为、男女买家交易对比和男女买家各个年龄段交易对比,我们基于抖音电商平台爬取的数据展开了本次实验。
数据的爬取与清洗
数据格式
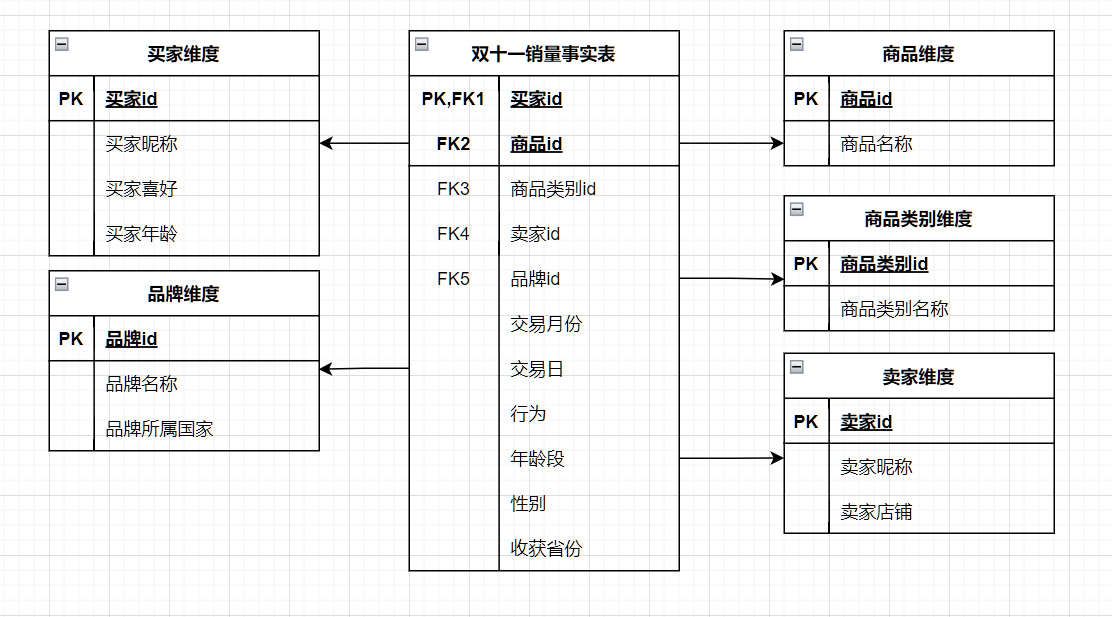
爬取到用户行为日志文件user_log.csv。其数据格式定义为:
1.user_id | 买家id
2.item_id | 商品id
3.cat_id | 商品类别id
4.merchant_id | 卖家id
5.brand_id | 品牌id
6.month | 交易时间:月
7.day | 交易时间: 日
8.action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
9.age_range | 买家年龄分段,1表示年龄<18,2表示年龄在18到24岁之间,3表示年龄在25到29岁,4表示年龄在30到34岁,5表示35到39,6表示40到49,7表示年龄>=50,8表示0,NULL表示未知
10.gender | 性别:0表示女性,1表示男性,2和NULL表示未知
11.province | 收货地址省份
数据清洗(数据预处理)
- 删除文件第一行数据,即字段名称
- 获取数据集中前150000条数据
- 导入数据库
数据仓库
支持向量机SVM分类器预测
预测回头客伪代码:
1 | |
数据可视化